
개발자로 후회없는 삶 살기
[문법] 자바 입력 데이터 저장 방식 본문
서론
※ 과거에 기록한 내용에서 중요한 부분만 발췌하여 모두가 이해하기 쉽게 다시 서술한다.
본론
- 자바의 인코딩 방식
1. 자바 내부적으로는 문자열이 UTF16으로 인코딩 된다.
2. 문자열 송/수신을 위해 직렬화가 필요할 때는 변형된 UTF8을 사용한다.
3. 문자열 입/출력에서는 사용자 지정 인코딩 or OS 기본 인코딩 방식으로 문자열을 인코딩한다.
자바의 인코딩 방식은 상황에 따라 다르며, 내부 메모리 상에서 처리되는 것과는 다르다.
유니코드, 아스키코드 : 문자를 컴퓨터로 표현하기 위해 고유한 숫자와 매칭한 코드 집합
UTF-8 : 가변 길이 유니코드 인코딩으로 특정 문자를 바이트로 변환하는 방법 (영어 1B, 한글 3B), 8은 1B를 나타내지만 아스키 문자에 대해 1바이트를 사용하며, 그 이외의 문자들은 더 많은 B를 사용
UTF-16 : 대부분의 문자를 2B로 인코딩하고 일부 문자를 4B로 인코딩
위 설명으로 봤을 때, 8과 16이 고정된 것은 아니며 기본적으로 1B와 2B를 사용하지만, 다양한 언어에 따라 더 많은 바이트로 표현되어진다.
🚨 UTF-8의 인코딩

어떤 문자가 유니코드 128에 대응될 때 인코딩되는 과정을 알아보자
1. 유니코드 인코딩 방식은 유니 코드 포인트의 길이를 4자리로 표준화하기 위해 16진수 4자리를 맞추고 필요한 만큼 앞을 0으로 채운다. 128은 U+0080이고 이는 16진수 0x0080, 2진수로 00000000 10000000 이다.
2. UTF8에서는 코드 포인트라는 구간 별 범위를 두고 구간마다 인코딩 패턴이 다르다. 0080의 인코딩 패턴은 110xxxxx 10xxxxxx이다.
3. 이때 x 11 자리를 2진수에서 가져와서 넣어주면 128은 11000010 10000000으로 인코딩 된다. 유니코드 128에 대응되는 문자는 이러한 이진수로 인코딩되어 컴퓨터에 저장된다.
인코딩 방식이 UTF8인 OS에서 메모장에 문자를 적고 저장하면 위와 같은 순서로 인코딩되어 컴퓨터에 저장된다.
-> 자바 메모리에 올라가는 과정
OS의 기본 인코딩 방식이 UTF8이라면,
1. UTF8로 입력(OS 인코딩을 따름)
2. 송수신에서 변형된 UTF8로 인코딩
3. 자바 File Encodings 방식에 따라 메모리에 로딩
4. 송수신에서 변형된 UTF8로 인코딩
5. UTF8로 출력
OS에 지정된 기본 인코딩 방식으로 입력 받고, 변형된 UTF8과 UTF16을 거쳐 메모리에 올라가고 출력 시 다시 UTF8로 출력된다.
-> 용어 정리
대부분의 인코딩 방식은 1 ~ 127까지는 패턴을 사용하지 않고 그대로 인코딩하기 때문에 인코딩 결과가 동일하다. 따라서 자바 char에 문자를 저장하여 int 값으로 변환할 때 나오는 숫자를 아스키코드라고 말하는 것은 100% 정답은 아니며 이는 1 ~ 127까지만 해당한다. 그 외 숫자들은 자바 인코딩 방식으로 메모리에 올라간 데이터를 UTF8로 출력된 값이라 봐야 한다.
UTF8 : 유니코드 인코딩 방식
MS949 : MS 계열 코드 인코딩 방식
자바 char의 int 값 : 자바 인코딩 방식으로 메모리에 올라간 데이터를 UTF8로 출력한 값
- 스트림이란?
하나의 방향으로 흘러가는 흐름으로 빨대의 입력과 흐름, 출력을 예로 들 수 있다. 단방향이기 때문에 목적에 따라 독립적으로 존재하며 입력을 용도로 InputStream, 출력을 용도로 OutputStream이 있다.
-> System.in과 inputstream의 관계
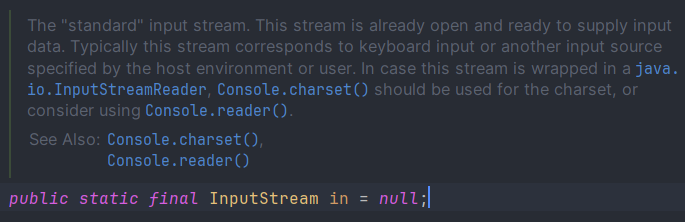
System 클래스에 들어가 보면 in은 InputStream 타입의 정적 변수이다. InputStream은 표준 입력 스트림으로 키보드를 치거나 터미널 입력을 넣어주는 것들이 연결된다.
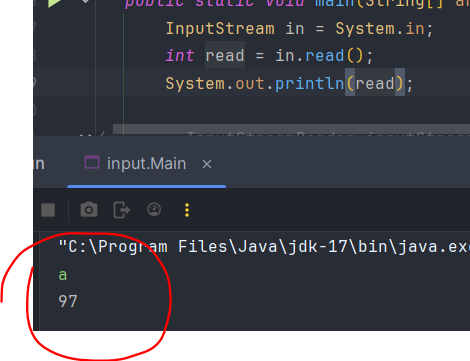
이것만 사용해도 입력을 받을 수 있으며, read() 입력 메서드로 가능하다.
🚨 97 출력 과정
1. OS 인코딩 방식으로 입력 a가 인코딩 됨
2. 송수신 될 때 변형된 UTF8
3. 출력을 위해 자바 메모리에 UTF16
4. 송수신 될 때 변형된 UTF8
5. UTF8로 디코딩 되어 a의 유니코드 값이 출력
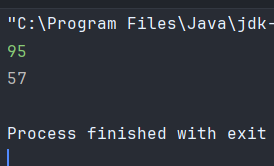
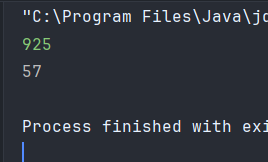
inputstream의 read 입력 메서드는 정수형으로 저장되고 자바에서 정수는 해당 파일 인코딩 형식으로 저장되고 read() 입력 메서드는 1B 단위만 읽는다.
🚨 이유
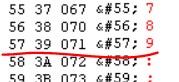
컴퓨터의 모든 데이터는 바이트 단위 데이터로 구성되고 저장된다. InputStream이 가장 기본적인 입력스트림이고 바이트 단위로 데이터를 보내며 read는 1바이트 단위로 읽어 들일고 2B 이상으로 입력받으면 1B 값만 읽고 나머지는 스트림에만 남아있다. 따라서 95나 925나 1B의 '9'만 정수형으로 불러오는 것을 알 수 있다.
- 불편한 점
1B 단위로 밖에 읽을 수 없다. 따라서 957은 read()를 세번 써야 한다. 이렇게 바이트 단위로 주고 받는 스트림을 바이트 스트림이라고도 한다.
public class Main {
public static void main(String[] args) throws IOException {
InputStream in = System.in;
byte[] a = new byte[3];
in.read(a);
for (byte b : a) {
System.out.println(b);
}
}
}따라서 여러 문자를 읽으려면 배열을 만들어야 하고 가변일 경우 처리하기 어렵다.
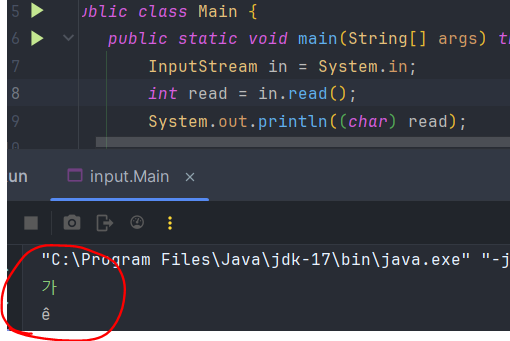
또한, 한글을 읽을 수 없다. UTF8에서 한글은 3B로 인코딩 되므로 3B가 모두 모여 하나의 문자가 되야 하는데 1B밖에 읽지 못하고 나머지 바이트는 스트림에 남아있다.
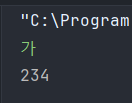

10진수로는 234가 나오는데 UTF8 인코딩 테이블을 보면 [234, 176, 128]이 합쳐 '가'로 표현된다. 가는 한글이라서 3B로 인코딩되는데 그중 첫 B만 읽을 수 있다.
- Scanner
스캐너에서 어느 경로를 통해 입력을 받게 되는 지 알아보자. Scanner(System.in)은 입력 바이트 스트림인 InputStream을 통해 표준 입력받으려고 하는 것임을 알 수 있다.
-> 스캐너에 왜 입력 스트림이 들어가는 걸까?

스캐너 내부를 보면 생성자에 InputStream 을 인자로 받고 InputStreamReader 로 한 번 더 감싼다.
🚨 InputStream과 InputStreamReader의 차이
InputStreamReader은 1B만 읽어서 한글을 읽지 못하는 InputStream과 같은 문제를 해결하기 위해 확장 버전으로 나온 것이다.
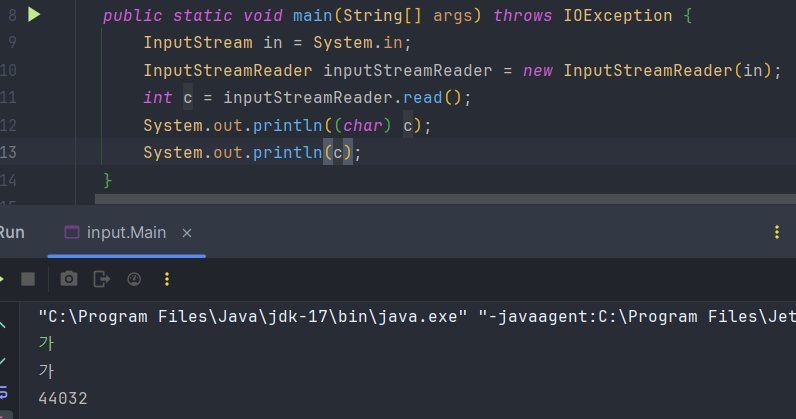
InputStreamReader 는 inputstream을 인자로 받고 바이트 단위를 문자 단위로 변형하는 중개자 역할을 한다. 따라서 read() 입력 메서드로 한글을 입력 받을 수 있다. 이러한 InputStreamReader 을 문자 스트림이라고 한다. 44032는 문자 '가'를 출력하기 위해 자바 메모리에 UTF16으로 인코딩 한 값 0xAC00이다.
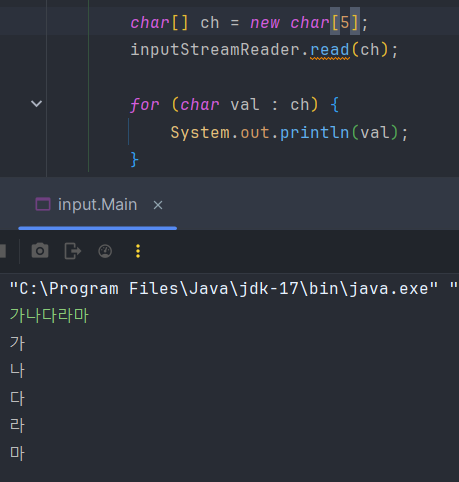
지금까지 바이트 단위를 문자 단위로 변환하여 편리해졌지만, 문자 단위라서 내부에 버퍼가 없고, 문자열 단위를 처리할 수 없어서 문자열을 입력 받기 위해서는 배열을 선언해 주어야 한다.
-> BufferedReader
BufferedReader도 비슷한 원리이다. InputStream으로 바이트 데이터를 받고 InputStreamReader로 문자로 변형하는 것은 동일하다. BufferedReader는 버퍼를 사용하여 문자를 쌓아두고 한 번에 문자열처럼 보내버리는게 가능하다.
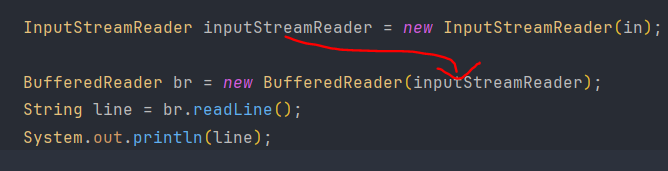
inputstreamreader을 인자로 받는다. 사용해보면 문자열을 받아들일 수 있으며, 내부에 배열이 존재하여 문자열 처리가 가능하다.
버퍼가 있는 스트림
별다른 검증 X
개행이 입력되거나 버퍼가 꽉차면 버퍼를 비우며 문자열 데이터로 내보냄
별도의 정규식 검증은 하지 않기 때문에 속도가 빠르다. 따라서 성능을 고려한 프로그램에서는 BufferedReader를 사용하는 것이 용이하다. 점점 문자를 입력 받는 방법이 개선되고 있다.
-> 스캐너는?
지금까지 공부하면서 바이트 단위에서 문자 단위, 그리고 문자열까지 개선해온 것을 확인할 수 있었다. 그러면 스캐너의 특징은 무엇일까?
✅ 정확도 VS 성능
private String buildIntegerPatternString() {
String radixDigits = digits.substring(0, radix);
// \\p{javaDigit} is not guaranteed to be appropriate
// here but what can we do? The final authority will be
// whatever parse method is invoked, so ultimately the
// Scanner will do the right thing
String digit = "((?i)["+radixDigits+"\\p{javaDigit}])";
String groupedNumeral = "("+non0Digit+digit+"?"+digit+"?("+
groupSeparator+digit+digit+digit+")+)";
// digit++ is the possessive form which is necessary for reducing
// backtracking that would otherwise cause unacceptable performance
String numeral = "(("+ digit+"++)|"+groupedNumeral+")";
String javaStyleInteger = "([-+]?(" + numeral + "))";
String negativeInteger = negativePrefix + numeral + negativeSuffix;
String positiveInteger = positivePrefix + numeral + positiveSuffix;
return "("+ javaStyleInteger + ")|(" +
positiveInteger + ")|(" +
negativeInteger + ")";
}스캐너 역시 내부에 배열을 가지고 문자열을 읽어들일 수 있다. 입력을 받을 때 정규식 검증을 하기 때문에 오버헤드가 발생하여 느리지만, 입력에 성공한 문자는 정확성을 보장한다.
※ 자바의 스트림
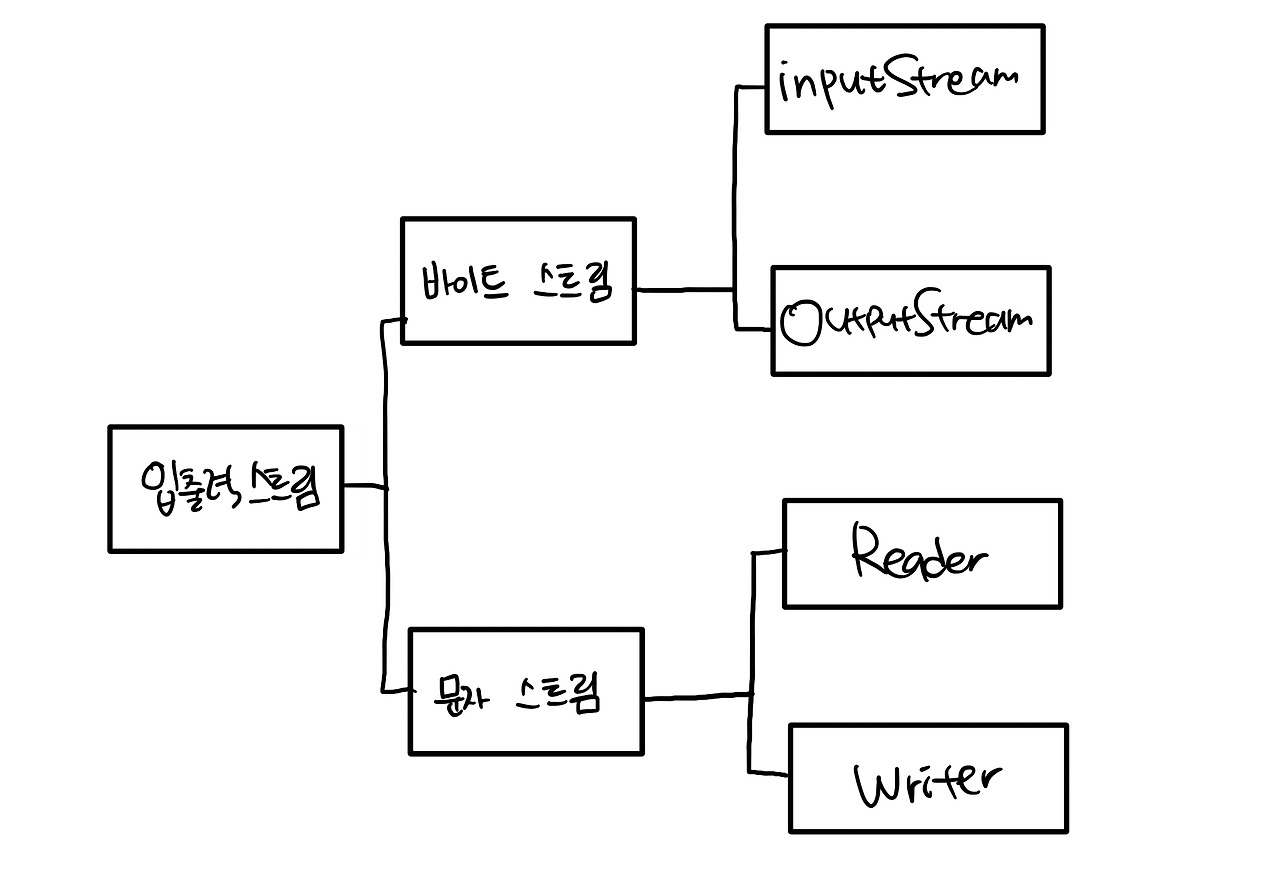
보통 Stream이 붙으면 바이트 단위이고 붙지 않으면 문자 단위이다.
참고
'[백엔드] > [Java | 학습기록]' 카테고리의 다른 글
| [문법] 오류를 핸들링하는 방법 (0) | 2024.06.05 |
|---|---|
| [문법] try-with-resources를 사용해야 하는 이유 (0) | 2024.05.29 |
| [문법] Comparator, Comparable 정렬 원리 (0) | 2024.05.27 |
| [문법] 인터페이스의 익명 객체 람다 (0) | 2024.05.25 |
| [문법] 객체 상수를 편리하게 다룰 수 있는 Enum 타입 (0) | 2024.05.23 |



