
개발자로 후회없는 삶 살기
Pytorch PART.Pytorch 탬플릿 Base 파일 관리 및 활용 본문
서론
상속의 개념을 적용하여 Base 모듈과 Config 파서로 클라이언트 코드는 전혀 변경하지 않고 기능을 추가해 보겠습니다.
본론
- 깃허브
https://github.com/SangBeom-Hahn/Practical_Pytorch
GitHub - SangBeom-Hahn/Practical_Pytorch: 실전 Pytorch 탬플릿 구축 공간
실전 Pytorch 탬플릿 구축 공간. Contribute to SangBeom-Hahn/Practical_Pytorch development by creating an account on GitHub.
github.com
- main()이 데이터 로더를 불러오는 방식에 대한 의문

파이토치 탬플릿 main 함수를 보면 config 파일에 module data라는 것을 넣고

config 파일에 원하는 데이터 로더를 연결하면 데이터 로더를 불러와 사용할 수 있도록 설계되어 있습니다.

또한 원하는 커스텀 로더를 만들고 Base 로더에게 상속 받으면 편리하게 사용할 수 있습니다. 이는 config 파일을 확장성있게 사용할 수 있는 유용한 기능으로 OCP 원칙을 지킬 수 있습니다. 즉, 코드는 변경하지 않고 config 파일만 바꾸면 원하는 기능을 할 수 있습니다. 이번에는 이와 같은 동작 원리를 알아보고 커스텀 데이터 로더에 적용해 봅니다.

module_data는 data_loader라는 패키지에 data_loaders라는 모듈을 의미합니다.

dir 구조를 보면 다음과 같이 되어 있습니다.

data_loaders 모듈에는 Mnist 데이터 로더가 하나 있습니다.

config의 getattr을 사용해서 클래스들을 모아 놓을 모듈과 모듈 이름을 인자로 받으면 원하는 모듈을 OCP 원칙을 지키면서 편리하게 반환할 수 있는 구조입니다. 불러와서 사용할 커스텀 로드들을 모아 놓은 모듈 명을 data_loaders로 정하고 내부에 로더들을 정의하겠습니다.
1. 베이스 로더 생성
먼저 간단하게 붓꽃 데이터 로더를 만들어 보겠습니다. 위에서 말했듯이 데이터 로더를 편리하게 사용하기 위해 Base 데이터 로더를 만들고 이를 상속 받는 구현체로 붓꽃 데이터 로더를 만들 것입니다. 이는 모델, 학습기 모두 해당되는 내용으로 구현체를 적절히 생성하고 수정해서 보다 효율적인 프로젝트를 진행할 수 있습니다.

보통 데이터 셋은 커스터마이즈 해왔지만, 간단히 로더는 불러와 사용합니다. 하지만 데이터 로더를 커스터마이즈하면 더욱 미세 조정할 수 있습니다. 부모 클래스로 사용된 Base 데이터 로더를 간단하게 정의하였습니다.

Base 파일 들을 패키지로 등록하여 외부 패키지에서 사용할 수 있도록 만듭니다.
2. 커스텀 데이터 로더 생성
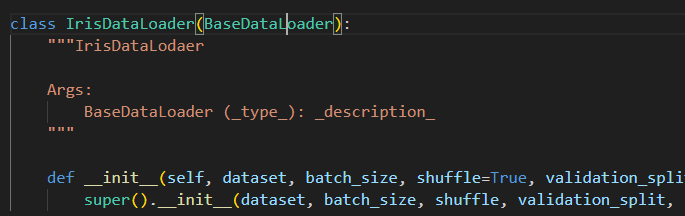
이제 Base 데이터 로더를 상속받을 커스텀 데이터 로더를 구현체로 만들겠습니다. 필요한 유틸 메서드들은 base에 작성을 해 두었으니 생성자만 있으면 됩니다.
3. 베이스, 구현체 데이터 셋 생성

데이터 로더에 삽입할 데이터 셋 클래스를 동일한 구조의 Base, 구현체로 만들어 보겠습니다.

데이터 셋을 데이터 별로 여러개 만들 것이므로 증강도 각각 만들어 주었습니다. 궁극적으로 학습 코드에서는 데이터 셋을 수정하는 코드가 없어지게 되고 Config 파일만 조작하면 원하는 데이터를 Feeding 할 수 있으며 추후 다른 모양의 데이터 셋을 구현해야 할 경우 편리하게 활용할 수 있습니다.
- 커스텀 데이터 로더 추출
def init_data_loader(self, name, module, *args, **kwargs):
module_name = self[name]["type"]
# 데이터 셋 추출
dataset = self.init_obj("dataset", module_dataset)
# 데이터 로더 생성자에 데이터 셋을 가장 먼저 넣기
module_args = {"dataset" : dataset}
module_args.update(self[name]['args'])
print(module_args)
return getattr(module, module_name)(*args, **module_args)이제 위에서 만든 데이터 관련 모듈들을 OCP 원칙에 맞게 추출하는 코드를 작성합니다. 데이터 로더의 생성자에 필요한 파라미터들을 config에서 args로 꺼내고 데이터 셋은 별도로 추출한 후 getattr로 원하는 데이터 로더를 반환합니다.

학습 시에 config 파일에 data_loaders와 datasets에 정의된 커스텀 모듈들 중 원하는 모듈을 명시하고 위 메서드를 호출하면 사용자 입장에서는 간편하게 로더를 추출할 수 있습니다. config 파일만 변경되지 클라이언트 코드는 전혀 변경이 일어나지 않습니다. 이렇게 구현을 완성합니다.


config 파일을 설정하고 코드를 실행해보면

config에 명시한 IrisDataLoader가 반환되는 것을 확인할 수 있습니다.
'[AI] > [딥러닝 | 이슈해결]' 카테고리의 다른 글
| Augmentation PART.albumentation 활용 (2) | 2023.12.19 |
|---|---|
| [최적화] GPU 풀 구현기 1 (0) | 2023.12.09 |
| Pytorch PART.데이터 로더, 폴더 활용(Collate, Sampler 등) (0) | 2023.12.04 |
| Pytorch PART.논문을 코드로 구현하는 능력(ResNet) (0) | 2023.11.28 |
| PyTorch PART.PyTorch 탬플릿 Config 파일 활용 (0) | 2023.11.19 |



