
개발자로 후회없는 삶 살기
spring PART.HTTP의 모든 것 1 본문
서론
※ 이 포스트는 다음 강의의 학습이 목표임을 밝힙니다.
https://www.inflearn.com/roadmaps/373
우아한형제들 최연소 기술이사 김영한의 스프링 완전 정복 - 인프런 | 로드맵
Spring, MVC 스킬을 학습할 수 있는 개발 · 프로그래밍 로드맵을 인프런에서 만나보세요.
www.inflearn.com
본론
- 인터넷 네트워크

인터넷에서 컴퓨터 둘은 멀리 떨어진 클라와 서버 사이에 인터넷 망이 있어서 광캐이블, 인공위성을 거쳐서 전달된다. 그때 수 많은 복잡한 과정을 어떻게 거쳐서 목적지까지 갈까를 이해해보자 이를 위해 IP를 알아야한다.
- IP


이게 IP 주소로 가능해진다. 클라와 서버가 IP가 있고 이 둘의 집 주소이다. 메세지를 보낼 때 보내는 사람 주소, 받을 사람 주소를 적고 보낼 메세지를 넣고 인터넷에 던진다. 그러면 인터넷 프로토콜에 맞게 인터넷 망에서 전달 전달해서 목적지로 간다.
-> 한계
IP로는 한계가 있다.
1. 비 연결성 :상대 IP의 컴이 꺼져있으면 받았나 안받았나 모른다.
2. 비 신뢰성 : 패캣이 중간에서 사라질 수 있다.
3. 프로그램 구분 : 하나의 Ip에서 음악도 듣고 게임도 하면 구분이 안된다.
- TCP

이런 한계를 극복한게 TCP이다. 인터넷 계층 위에 tcp 전송 계층이 있다. IP위에 TCP를 올려서 이를 보완해 주는 것이다.

IP 패킷안에 TCP 정보가 들어간게 TCP/IP 패킷이다. IP로는 해결이 안됐던 정보들이 들어가 있다.
-> 한계 해결
1. 3 way handshake

이 3번의 악수가 성공해야 상대 상태가 양호함을 알 수 있고 그제서야 메세지를 보낸다.
2. 데이터 전달 보장

3. Ip에는 포트가 없는데 TCP에는 포트가 있어서 프로그램 구분을 한다.
- 포트

한 pc에서 게임하면서 화상 통화하면 여러개와 통신을 해야한다. TCP에는 출발지 포트와 목적지 포트가 있다.
같은 IP 내에서 프로세스를 구분한다.
- DNS

IP는 숫자라서 어렵다. 도메인 네임 시스템은 중간에 서버가 있는데 www.naver.com을 IP 번호로 바꿔준다.
- URI

uniform resource identifier로 리소르를 식별하는 통합된 방법이라는 뜻이다. URI는 리소스를 식별하는 것으로 주민번호를 식별하듯이 자원이 어디에 있는지 자원 자체를 식별하는 방법이다.
-> 2가지가 있다.

1. URL : 리소스 로케이터로 리소스의 위치를 알려주는 것 한상범의 위치를 알려준다.
2. URN : 리소스의 이름으로 한상범의 위치가 있다면 그냥 한상범이다.
-> 예시

그림을 보면 위치와 이름이다. 이름으로는 찾을 수 없어서 URL만 쓰는 것이다. URN 이름만으로 실제 리소스를 찾는 방법이 없다.
- URI

URI를 URL이 포함한다. 리소스를 식별하는 통일된 방식으로 리소스틑 URI로 식별할 수 있는 모든 것으로 html뿐만 아니라 실시간 교통 정보, 나라 이름 이런것이 다 리소스이다.
우리는 그 중 URL만 쓰고 웹 브라우저에 URL을 치면 이 리소스가 여기에 있을 거라고 말해주는 것이다.
-> URL 분석

스키마 : 스키마에 프로토콜이 들어가고 어떤 방식으로 자원에 접근할 것인가 하는 클라와 서버의 약속이다.
host : 도메인 명/ 포트 : 보통 생략한다./ 경로 : /home/file.jpg의 dir 계층 정보이다.
쿼리 : 키=벨류의 형태로 쿼리 파라미터, 쿼리 스트링으로 불린다. 스트링인 이유는 숫자를 적어도 다 문자로 넘어가기 때문이다.
- 웹 브라우저의 요청 흐름

먼저 DNS를 조회해서 IP를 얻고 https는 포트 443으로정보를 얻는다. 그리고 http 요청 메서드를 만든다.

요청 메세지는 이렇게 생겼다.

패킷을 만들 때 그 안에 http 메세지가 담겨서 나간다.

서버가 패킷을 받으면 패킷을 벗겨서 http 요청 메세지를 받는다. 응답도 같은 방식으로 하고 클라가 패킷을 받아서 응답 메세지를 받는 형식이다.
- http의 모든 것

하이퍼 텍스트를 전송하는 것으로 시작한 프로토콜이었는데 지금은 이미지, 음성, json 등 모든 것을 http로 전송을 한다.


지금 http 1.1 버전을 리팩토링한 2, 3을 쓰고 있다. 1.1이 제일 중요하고 2, 3은 기능 개선만 한 것이다. h3가 http3이다.
-> 특징
클라, 서버 구조이고 무상태, 비연결성, 단순하고 확장 가능하다.
- 클라, 서버 구조

클라가 req하고 서버가 resp로 응답하는 구조이다. 이렇게 분리하는게 되게 중요한게 예전에는 클라와 서버를 분리하지 않고 하나로 묶어놨다.
> 이제는 분리하고 데이터와 로직은 서버에 다 밀어 넣고 클라는 UI에만 집중한다.
- 무상태 프로토콜
서버가 클라이언트의 상태를 보존하지 않는다.
1. stateful


고객 A가 노트북을 구매했다. 점원은 노트북의 상태를 유지한다. 2개 구매하면 점원은 200만원 이라는 것을 안다. 점원은 고객이 노트북을 2개 구매하는 상태를 유지하고 있다. 근데 이렇게 하면 중간에 점원이 바뀌면 대화가 안된다.
2. stateless

점원이 고객의 상태를 유지하지 않은 상태에서 유지하는 것처럼 하려면 어떻게 고객이 길게 말한다. "노트북 2개를 신용카드로 구매할요!"라고 한다. 그럼 점원은 고객의 한 마디만으로도 대화를 할 수 있다.

> 근데 이렇게 하면 중간에 점원이 바뀌어도 주문이 가능하다. 상태 유지에서는 다른 점원으로 바뀌면 문맥이 사라져서 서비스 장애가 일어난다. 근데 무상태에서는 고객이 필요한 데이터를 점원에게 다 넣어준다. > 클라 서버 구조에서는 이렇게 하면 서버의 무한한 확장성을 가진다. 거의 무한 증식을 할 수 있다.
-> 차이

무상태면 중간에 점원이 바뀌어도 상관없다. 즉 마트 입장에서는 갑자기 고객이 막 증가한다면 그래도 점원을 대거 투입해도 된다는 것이다.
> 백엔드 개발자 입장에서는 무상태면 갑자기 클라가 몰려도 서버를 대거 투입할 수 있다. 무상태는 응답 서버를 쉽게 바꿀 수 있다. 왜냐면 상태 유지를 하지 않기 때문이다.
-> 그림


상태 유지는 클라 A가 서버 1과만 통신해야하고 만약 서버 1이 죽어버리면 클라 A는 처음부터 다시 통신해야한
다.


무상태는 클라가 처음 요청할 때부터 필요한 데이터를 다 담아서 요청한다. 노트북 2개를 신용카드로 구입할 거야라고 서버에게 보내면 서버는 상태를 보관하지 않고 필요한 응답만 한다.
중간에 서버 1이 죽으면 중계 서버에서 서버 2로 중계를 바꿔도 상관없다.
-> 실무 한계

항상 무상태로 설계할 수는 없다. 단순한 소개 페이지는 상태를 유지할 필요가 없어서 무상태로 설계하기 쉽다. 근데 로그인은 로그인을 한 것을 서버에서 상태를 유지해야한다. 그래서 일반적으로 이를 어떻게 구현하냐면 브라우저의 쿠키와 서버의 세션을 조합해서 상태를 유지하는 기능을 한다. 그렇지만 상태 유지는 정말 최소한으로 상태를 유지해야할 때만 사용해야한다. 또한 데이터를 너무 많이 보낸다는 단점이 있다.
- 비연결성

tcp ip는 일반적으로 연결을 유지한다. 연결을 유지한채로 요청을하고 응답을 받는다. 클라 2가 요청을 해도 클라 1의 연결이 유지가 되고 서버의 자원이 소모가 된다.
이 단점은 요청을 하지 않아도 연결을 유지한다는 자원 소모이다.
-> 연결을 유지하지 않는 모델

요청하고 응답하면 연결을 끊는다. 이러면 자원을 최소한으로 줄인다. 이게 3개만 그려서 그렇지 1억대면 정말 좋다.


http는 기본적으로 연결을 유지하지 않는 모델이다. 1시간동안 수천명이 서비스해도 실제 서버에서 동시에 처리하는 요청은 수십개 이하로 매우 적음 계속 검색 버튼만 누르고 있는게 아니므로 그렇다.
-> 단점
tcp ip 연결을 새로 맺어야해서 3번 악수 시간이 추가된다. 또한 김밥 하나 검색할 때마다 계속 연결을 하면 그때마다 html , css를 계속 가져온다. 이를 지속 연결로 해결한다. 이런게 있다 정도만 알면된다.
-> 스테이스리스를 기억하자

정말 같은 시간에 딱 맞춰서 일어나는 선착순 이벤트는 정말 동시에 수 만명이 버튼을 누른다. 이러면 비 연결성이 소용이 없다. 그래도 어떻게든 스테이스 리스를 하도록 생각을 해야한다.
- http 메세지
http는 요청 메세지와 응답 메세지의 구조가 약간 다르다.
-> 메세지 전체 구조

1. 시작라인
2. 헤더
3. 공백
4. 메세지 바디
-> 요청 메세지

1. get, path, 쿼리 파라미터, 프로토콜 버전이 요청 메세지의 시작 라인
2. 헤더
3. 메세지 바디에 넣을게 없으면 비워둠
-> 응답 메시지

1. 시작라인이 다르고 나머지는 요청과 같다. http 버전과 200 Ok이다.
2. 헤더
3. 공백
4. 응답 메세지로 보통 이게 html이면 html 내용이 들어있다.
- 요청 메세지의 시작 라인(요청과 응답이 이것만 다르다고 했다.)

메서드, 경로(request target), 버전이 들어간다.
1) 메서드

get은 서버에게 이 리소스를 달라고 하는 것, post는 내가 리소스의 데이터를 줄테니 너가 처리해달라는 의미
2) 경로(요청 대상 = request target)

보통 절대 경로에 ?쿼리를 합쳐서 넣는다.
3) http 버전
- 응답 메세지의 시작라인

http 버전, status code가 들어간다. 클라의 요청이 성공했는지 실패했는지 나타낸다. 200은 성공 400은 클라의 요청 오류, 500은 서버 내부 오류이다. ok는 그냥 상태 코드의 사람이 볼 수 있는 글이다.
- 헤더

헤더 필드 : 필드 이름 ":" (OWS) 필드 벨류 ex) Host: www.google.com/ Content-Type:text

용도는 http 전송에 필요한 모든 부가 정보가 다 들어있다. 예를 들어서 메세지 바디가 html인지 xml인지에 대한 설명도 들어가 있고 메시지 바디의 크기, 메세지 바디의 압축여부, 인증 정보, 요청 클라의 웹 브라우저가 크롬인지, 캐시 정보 등의 들어있다.
- 메시지 바디

실제 전송할 데이터인 html 문서, 이미지, 영상, json등등 byte로 표현할 수 있는 모든 데이터 전송 가능하다. 압축해서 보낼 수도 있다.
- http api 만들어보기
갑자기 실무에 투입됐다고 생각하고 http api를 만들어 보자
-> 요구사항
회원 정보를 관리하는 http api를 만들어봐라 회원 목록 조회, 회원 조회, 등록, 수정, 삭제도 해야한다.


-> API URI 설계
처음에 개발할 때 이렇게 한다. 회원 목록 조회네? 이름을 딱 맞게 지어야지~ 하고 회원 목록 조회니깐 read-member-list라고 지었다. 이렇게 URI을 만든다.
-> 이것이 정말 좋은 uri 설계일까?

uri 설계에서 가장 중요한 것은 리소스 식별이다.
-> 리소스가 뭘까?

리소스의 의미를 담아야한다. 회원을 등록하고 수정하고 조회하는게 리소스가 아니다. ex) "미네랄을 캐라"라고 하면 미네랄이 리소스이지 미네랄을 캐라가 리소스가 아니고 미네랄이 리소스이다. 회원이라는 개념 자체가 리소스이다.
-> 리소스를 어떻게 식별하는게 좋을까?

회원을 등록하고 수정하고 조회하는 것은 모두 배제한다. 그냥 회원이라는 것 자체만 리소스로 식별하고 회원 리소스를 uri에 맵핑하면된다.


그래서 이렇게 된다. 리소스를 리소스 답게 설계를 해야한다. uri는 계층 구조를 쓴다고 했다. 회원 목록 조회는 여러 멤버가 모여있는 것이니 members로 하고 회원 조회는 계층형구조라고 했으니 members 밑에 회원의 id가 들어오면 되겠다고 설계가 된다.
그 다음에 문제가 생긴다. 등록, 수정, 조회를 어떻게하지? 구분이 안된다. 리소스를 가지고 하면 uri 설계가 딱 막힌다.
-> 리소스와 행위를 분리

우리가 지금 배우는게 http 메서드이다. 리소스와 행위를 분리해야하고 가장 중요한 것은 리소스 자체를 식별하는 것이다. uri는 리소스만 식별한다. 리소스와 해당 리소스를 대상으로 하는 행위를 분리해야한다. 미네랄과 미네랄을 캐는 행위는 분리해야한다.
> uri는 이 리소스를 판별하는데 써야한다. 리소스의 행위를 판별하는데 쓰면 안된다. 리소스가 회원이고 행위가 조회, 등록, 삭제, 변경으로 분리를 할 수 있다. 리소스는 보통 명사(회원), 행위는 동사가 된다. 행위는 어떻게 구분하느냐? 이것을 다음시간에 배울 http 메서드가 이 역할을 대신해준다. 그러기 때문에 uri의 리소스만 식별해 놓으면 http 메서드인 get, post 등이 조회, 삭제, 수정을 대신해준다.
- http 메서드 get, post
메서드는 클라가 서버에 요청을 할 때 기대하는 행동이다. get은 달라는 거고 post는 내가 데이터를 줄 테니 등록하거나 처리해달라는 의미이다.
-> 종류

get은 리소스를 조회하는 것
post는 무조건 데이터를 담아서 클라가 서버에 보내야하고 요청 데이터를 줄테니 처리해달라는 것이다.
put은 클라에서 서버로 리소스를 보내는데 이 리소스로 대체해줘 ex) 파일을 폴더에 넣는 것이다.
patch는 이 리소스를 부분적으로 변경하는 것으로 ex) 회원의 이름을 바꾼다.
delete는 이 리소스를 삭제해 달라는 요청이다. (보면 진짜로 행위이네??)
※ 최근에는 리소스가 representation으로 바뀌었다.
1. get

이름 그대로 리소스를 조회하는 것이다. 이 path에 있는 자원을 달라는(조회) 것이다. get은 검색엔진에 내가 필요한 파라미터를 넘겨야하는데 이걸 쿼리 파라미터로 전달한다. get은 메세지 바디에 데이터를 넣어 전달할 수 있지만 권장하지 않는다. 쿼리 파라미터로 데이터를 전달한다.
-> 그림
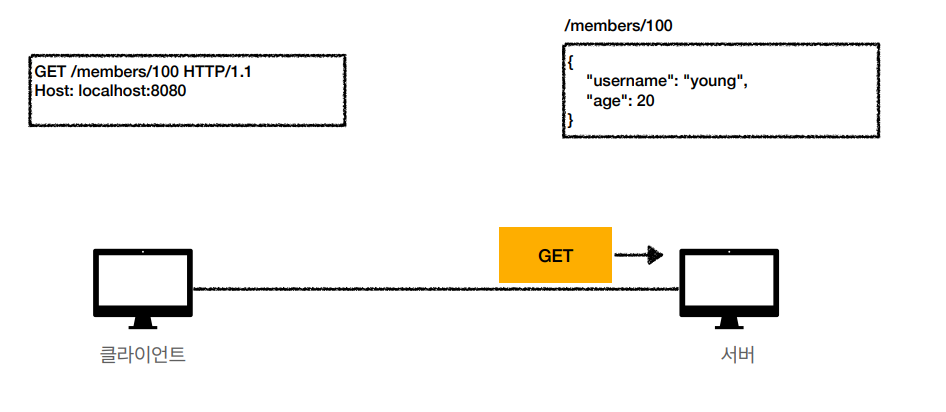
예를 들어 클라가 /members/100 슬러시 members에 100번 유저를 달라고 한다.
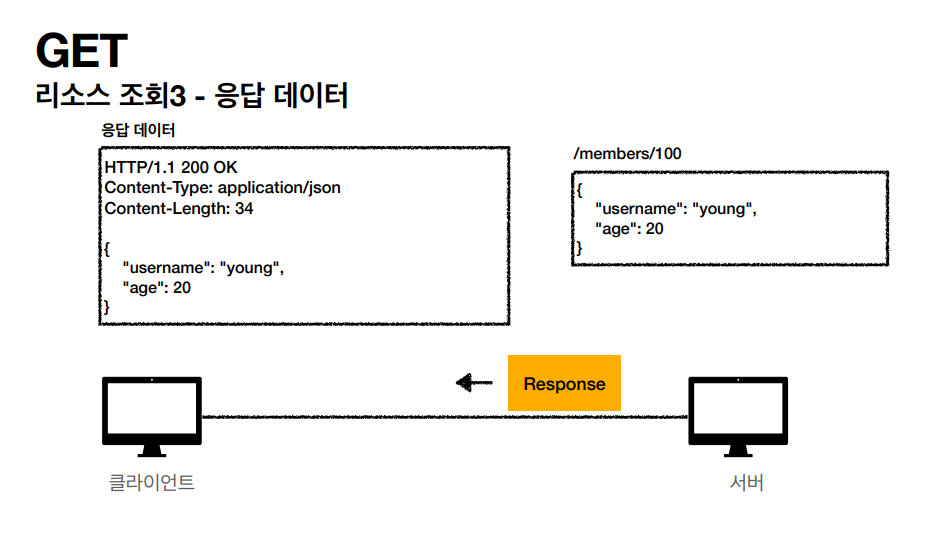
그러면 서버에서 get 메세지를 봐서 까보니깐 슬러시 members의 100번을 달라고 하니 내부 DB를 조회해서 http 응답 메세지를 만들어서 클라에게 보낸다. start line에 http, 200넣고 헤더에 content type, length 넣고 컨텐트 바디에 데이터를 넣어서 클라에게 메세지를 전달한다. 이 정보를 가지고 프론트에 정보를 그린다.
2. post

get은 요청할 때 데이터를 전달하지 않는데 post는 이런 의미이다. '요청할 때 서버에 데이터를 줄 거야. 이름은 hello고 age는 20을 줄테니깐 서버 네가 받아서 요청 데이터를 처리해줘"의미이다. 핵심은 메시지 바디를 통해 서버에게 요청 데이터를 처리해 달라는 얘기다. 주로 등록에 많이 쓴다.
-> 그림

/members에 메시지를 보낼 것이다. 그러면 약속을 해놔야한다. "클라야 너가 /members라고 post라고 보내면 그 데이터는 내가 저장할 거야, 처리할 거야"라고 미리 약속을 해 놓는다.

> 클라가 post로 슬러시 members에 보내면 서버에서 데이터를 받아서 바디를 열어서 서버에서 db에 등록하고 그게 신규 아이디를 만들고 신규 리소스 식별자를 생성한다. 여기서는 100번이다. 그 다음 이렇게 응답한다.

신규로 데이터가 생성이 되면 보통 http 201 created라고 보낸다. 그리고 이 자원이 생성된 path를 보낸다. 그리고 등록된 자원의 데이터도 보여준다.
-> post는 요청 데이터를 어떻게 처리하라는 뜻일까?

post가 의미가 되게 많다. 공부할 때 데이터를 등록한다고만 배우는데 그게 아니다. 공식 사이트에 이렇게 나와있다.
1) html form에 입력된 데이터를 처리 : 예를 들어서 html form에 입력한 정보로 회원가입, 주문 등에서 사용한다.
2) 게시판에 글쓰기 : 왜냐면 게시판에 글 쓰고 submit 누르면 그게 서버로 넘어가고 서버가 그 게시판에 글을 저장할 것이니
3) 서버가 아직 식별하지 않은 새 리소스를 생성 : 그림에서 본 신규 주문, 신규 회원을 생성하는 것
4) 기존 자원에 데이터 추가
+ 핵심은 리소스 uri( /members )에 post 요청이 오면 리소스마다 스스로 정해야하고 딱 정해진게 없다.
-> 정리

1) post는 여러가지 쓰임새가 있는데 주로 새 리소스를 생성하고 등록하는데 사용한다.
2) 요청 데이터를 처리하는데도 사용한다. 단순 데이터를 생성하고 변경하는 것을 넘어서 프로세스를 처리해야하는 경우
ex) 상품을 주문해서 결제 완료를 하면 사장님이 배달 시작 버튼을 누른다. 그럼 이걸 post로 보내야한다. 배달 시작이 되면 라이더 호출, 같은 큰 프로세스가 벌어질텐데 이때도 쓴다. 따라서 큰 프로세스를 처리해서 1)의 새로운 리소스가 생기지 않아도 post를 쓴다.
ex2) uri를 설계할 때 리소스 단위로 설계해야한다고 했다. 근데 어쩔 수 없이 리소스만으로 안될때가 있었다. 그럴때 이렇게 설계한다.
/orders/{orderId}/start-delivery
/orders에 {orderId} 주문 id가 100이다. 100에 start-delivery라고 uri를 만들 수 있다. 어? 아까 리소스와 행위를 나눠서 리소스만 uri로 설계하라고 하지 않았나? 그렇게 하면 매우 좋은데 그렇지 못하는 경우가 있다. 그럴때는 동사의 uri가 나올수있다.(컨트롤 uri) 기본적으로 최대한 리소스만으로 uri를 설계하되 어쩔 수 없는 부분은 컨트롤 uri로 한다. 컨트롤 uri에 post를 많이 쓴다.
3) 다른 메서드로 처리하기 애매한 경우
ex) json으로 조회하는 데이터를 넘겨야한다. 쿼리 스트링말고 뭔가 메시지 바디에 뭔가 넣고 싶어! 조회 용으로 메시지 바디에 넣고 싶은데 get은 권장하지 않다고 했다. 이런 경우에는 조회이지만 post로 쓴다.
-> 결론 : post는 모든 것을 다할 수 있다. 하지만 조회는 get으로 한다.
- put, patch, delete
-> put

리소스를 대체한다. 폴더에 파일을 복사하는 것과 같고 파일이 없으면 새로 생기고 같은게 있으면 덮어버린다.
put /members/100에 보내면 기존에 있으면 덮고 없으면 완전히 대체한다.
★ 중요한 건 post와 다른게 클라가 리소스 전체 경로를 알고 uri을 지정하는 것이다. post는 데이터 등록할 때 /members에 요청해서 클라는 100번에 만들어 질지 200에 될지 모른다. 근데 put은 클라가 리소스 위치를 알고 uri 지정한다.
-> 그림
1) 리소스가 있는 경우


100에 넣는다고 클라가 지정하면 리소스가 대체된다. 기존의 name이 young 이었는데 이제는 old로 된다.
2) 리소스가 없으면


신규 리소스 생성됨
3) 주의! 리소스를 완전히 대체한다.

나는 name은 놔두고 age만 바꾸고 싶어 그러면 name은 없어지고 age만 남는다.
- patch

age만 남는게 아니라 name은두고 age만 수정하고 싶은 경우에는 patch를 쓴다. 리소스를 부분 변경한다. http에서 patch를 못 받는 경우가 있는데 그때는 post를 쓴다.
- delete

리소스 제거
- http 메서드 속성

메서드마다 속성이 있다. 안전, 멱등, 캐시 가능이 메서드마다 다르다.
-> 안전

안전하다는 뜻은 호출해도 리소스가 변경이 되지 않는 다는 것이다. get은 안전한데 post, put, delete는 안전하지 않다.
-> 멱등

한 번 호출하든 두번 호출하든 100번 호출하든 결과가 똑같다. get, put, delete는 결과가 똑같다. 이때 클라가 똑같은 요청을 한다고 가정해야한다. put, delete도 같은 리소스를 덮고 삭제한다고 해야 멱등하다. 또한 외부 요인은 고려하지 않는다.
> post는 프로세스를 처리한다고 했다. 두번 결제하면 중복 결제가 된다. 그래서 멱등하지 않다. 사장님이 배송을 두번 눌러도 멱등하지 않다.
-> 캐시가능

이게 되게 중요하다. 응답 결과 리소스를 캐시에서 사용해도 되는가?이다. 웹 브라우저에 이미지 큰거를 요청한다. 그러면 또 같은 리소스를 요청할 필요가 없다. 그래서 내 로컬 pc 브라우저가 저장하고 있다. 간단하게 웹 브라우저가 이 리소스를 저장하고 있을 수 있냐 없냐이다.
get, head, post, patch는 캐시가 가능하고 실제로는 get, head 정도만 캐시로 사용한다.
'[백엔드] > [spring | 학습기록]' 카테고리의 다른 글
| spring PART.JSP MVC 패턴, 한계점 (0) | 2023.04.10 |
|---|---|
| spring PART.서블릿 jsp로 웹 어플리케이션 개발 (0) | 2023.04.10 |
| spring PART.서블릿 프로그래밍 개요 (0) | 2023.04.07 |
| spring PART.request scope (0) | 2023.04.02 |
| spring PART.빈 스코프 (0) | 2023.04.02 |



