
개발자로 후회없는 삶 살기
한국어 특화 CLIP 기반 K컨텐츠 이미지 생성 본문
서론
롯데 이노베이트에서 진행한 미션을 과정을 기록합니다.
본론
-> 전체 코드
- 프로젝트 주제
기존 text2img 이미지 생성 모델들은 영어 프롬프트를 기반으로 동작하므로, 한국어를 입력하면 다음과 같은 결과가 나옵니다.

프롬프트 :
"여름 날씨에 수영장에서 즐겁게 놀고 있는 가족의 모습. 수영장은 맑은 물과 다양한 수영 놀이 시설이 있으며, 가족들은 물속에서 즐거운 시간을 보내고 있습니다."
이는 한국어를 전혀 이해하지 못하고, 이미지 생성에 필요한 적절한 텍스트 임베딩을 하지 못하기 때문입니다.

프롬프트 :
"여름 날씨에 수영장에서 즐겁게 놀고 있는 가족의 모습. 수영장은 맑은 물과 다양한 수영 놀이 시설이 있으며, 가족들은 물속에서 즐거운 시간을 보내고 있습니다."
따라서, 한국어 텍스트를 이해하고, 해당 텍스트에 맞는 이미지를 생성할 수 있는 Stable Diffusion 모델을 만드는 것이 인턴십 미션입니다.

프롬프트 :
"사진 하단에는 확실한 나이든 사람이 있고, 주변 배경은 산과 숲으로 둘러싸여 있다, 백묘법 "
추가로, LoRA 방식으로 UNET을 학습시켜서, 한국을 나타낼 수 있는 LoRA를 여러개 만들고, 한국에 특화된 이미지 생성 모델을 만들어서, 특정 목적만을 위한 생성 AI를 개발합니다.

프롬프트 : "한복을 입고 꽃다발을 들고 있는 어린 소녀 사진이 있습니다."
위 사진들은 수목화, 한복 LoRA를 사용한 결과입니다. 이 역시 한국어를 이해하여 임베딩 결과를 생성할 수 있어야 합니다. 이러한 목표를 가지고 인턴십 미션을 진행합니다.
🚨 기존 방식의 문제점 분석
현재 서비스에 탑재된 이미지 생성은 장당 20초가 소요되며, 상당히 오래 걸리는 시간 때문에, 컴플레인이 발생하고 있다. 또한 동시 접속자를 생각해야 하는데, GPU 개수 제한으로 인해 무한정 대기가 발생하는데, 무한정 대기를 막기 위해, 타임아웃을 걸었고 이 때문에 마치 티켓팅처럼 타임아웃(웹, 쿠버네티스 두 곳) 발생 후 또 새로운 대기 순번을 받아서 계속 사용이 밀릴 수 있다.
✅ 오래 걸리는 이유가 뭔가?
1) 생성 모델은 내부 모델을 사용해서 시간이 적게 소요되지만, 영어 기반 모델이라서 한글 프롬프트를 영어로 번역하는 게 필요
2) 프롬프트 관련 번역, 토크나이즈 작업이 외부 API를 사용하는데, 외부 API 네트워크 IO, 번역 처리, 응답이 시간을 많이 소요
✅ 최종적으로 원하는 것은?
1) 한국어 기반 이미지 생성 모델 개발
2) 한국어 기반 이미지 생성 모델을 사용한 전체 프로세스 설계 및 구현
3) 추가적인 서비스 속도 개선
위와 같은 이유로 한국어 기반 이미지 생성기를 만들어야 합니다. 실제 서비스에 사용할 선행 연구를 진행하는 것이기 때문에, 속도와 성능을 최적화 해야합니다.
=> 세부 목표
1) 프로젝트 기획 및 타당성 분석
2) 한국어 CLIP 개발
3) 한국 특화 LoRA 개발
4) 서비스 개선을 위한 엔지니어링 최적화
- 프로젝트 시작
1. 프로젝트 기획 및 타당성 분석
목표를 달성하기 위한 타당성 분석을 수행했습니다.
1) 가능한 방법
① KoCLIP + SD
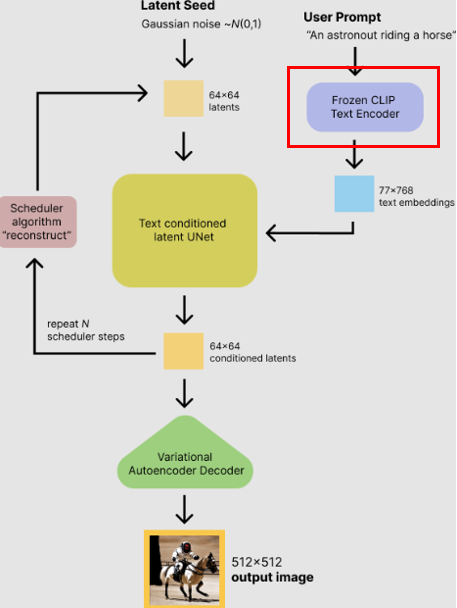
SD 파이프라인에는 OpenAI의 기학습 CLIP이 내장 되어있습니다. SD의 이미지 생성부는 텍스트 임베딩을 기반으로 이미지를 생성하므로, 텍스트 임베더를 한국어로 잘 만들면 문제를 해결할 수 있을 거라 생각했습니다.
실제로 CLIP을 교체하여 한국어를 이해하는 SD 레퍼런스가 있기에, 진행해도 좋다는 컨펌을 받았습니다.
② 성능 좋은 다른 Text-to-Image 방식 찾기
1) Parti 모델 ( [Parti Git] )에 이미지 300만 개 ( [AI hub] ) 학습
2) KoBERT ( [KoBERT Git] ) 로 텍스트 임베딩 ( torch.Size[1, 768] )
3) Text-to-Image 모델에 이미지 300만 개 학습
4) Text-to-image 모델에서 이미지 생성부는 freeze하고 text 인코더만 학습시키는 방법
SD 방식이 아닌 위 방법으로, 아예 새로운 이미지 생성기를 만들 수 있다고 생각했습니다.
③ 번역기를 이용한 방법
기존 방식과 동일하지만, 외부 API가 아닌, 내부에 독립적인 번역 모델을 띄워서 속도를 단축시키는 방법도 고려했습니다.
1) 한글 > 영어 번역
2) 영어 프롬프트를 기존 이미지 생성기에 입력

prompt = "라면을 먹고 있는 사람"
번역기를 사용하긴 하지만, 위와 같은 퀄리티의 이미지를 한국어로 생성할 수 있습니다.
2) 데이터 셋
1) ko clip 만들기 위한 한국어 - 영어 말뭉치
2) text to image 모델 전체 학습하기 위한 이미지-설명문 쌍 데이터 300만 개
CLIP과 이미지 생성부를 학습하기 위한 데이터 셋을 조사했습니다.
✅ 타당성 분석에 대한 피드백
1) 성능 좋은 다른 모델에 대하여 : A100 GPU 1대로 학습시키기에는 너무 시간이 오래 걸릴 것 같고, 데이터 수량도 300만 장이 부족하다고 예상된다. 일단 학습을 시켜보고 에폭당 로스 확인 후 전체 학습 시간을 예상하고 중간에 멈춰라
2) 번역기 사용한 모델은 메인 아이디어로 사용하기엔 힘들 것 같으니 결과 비교용으로 사용하면 좋을 것 같다.
(번역기 vs 텍스트 인코더 변경한 것 vs 이미지 인코더 변경한 것)
위와 같은 피드백으로, 우선 한국어 CLIP을 새로 학습시키고, SD에 교체하는 것으로 진행 방향을 잡았습니다.
2. 한국어 CLIP 개발
우선 CLIP이란 무엇이며, 왜 개발해야 하는지 알아봅니다.
Stable Diffusion은 프롬프트 텍스트를 입력으로 받는 이미지 생성 모델입니다. 이미지 생성 모델은 입력 벡터를 입력으로 벡터 값을 통해 생성하기에, 텍스트를 벡터로 임베딩하는 모듈이 필요하고, 그 모듈이 CLIP입니다. 이미지 생성기도 성능이 좋아야 하지만, 입력으로 들어오는 텍스트를 정확히 이해하지 못하면 생성기 성능은 아무런 의미가 없습니다. 따라서 한국어를 잘 이해하여 임베딩할 수 있는 CLIP을 만들고 이미지 생성기에 넣기 위한 모델 학습과 최적화를 진행합니다.
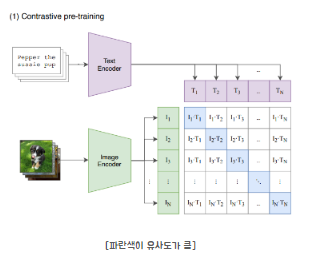
OpenAI에서 만든 기학습 CLIP은 이미지와 이미지에 대한 설명 텍스트 각각의 임베딩 결과의 차이가 적도록 학습한 이미지를 설명하는 텍스트 임베더입니다. 해당 텍스트 임베더는 프롬프트를 입력하면 이미지에 대한 프롬프트의 임베딩 결과를 출력합니다.
🚨 영어 임베더라는 문제점
하지만, 기학습 CLIP은 영어로 학습되어, 영어 임베딩만 가능하고, 한국어를 입력하면 전혀 다른 임베딩 벡터를 출력하는 문제가 있습니다.
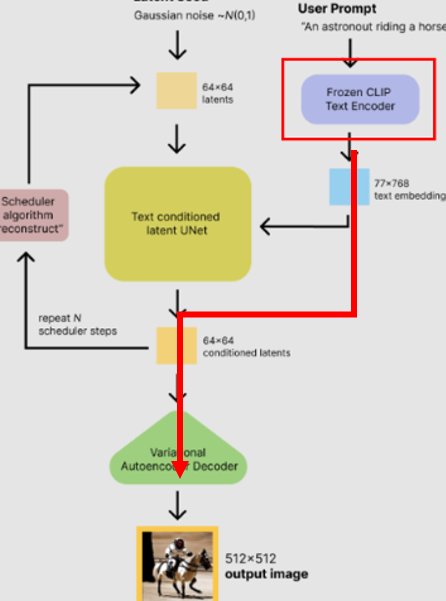
CLIP 출력이 이미지 생성 부의 입력으로 들어가는 프로세스에서 당연하게도, 입력이 달라지면 출력도 달라집니다.


프롬프트 : " 고양이"
동일 이미지 생성기에 대해서 영어 CLIP에 영어 프롬프트를 넣은 결과와 한국어를 넣은 결과는 너무도 차이가 큽니다. 더욱이 아예 한국어를 노이즈로 인식해서, 아무 이미지도 생성 안 되는 게 다반사입니다. 따라서 우리는 반드시 한국어로 학습된 CLIP이 필요합니다.
✅ 한국어 CLIP을 만드는 방법론 Distillation Knowledge
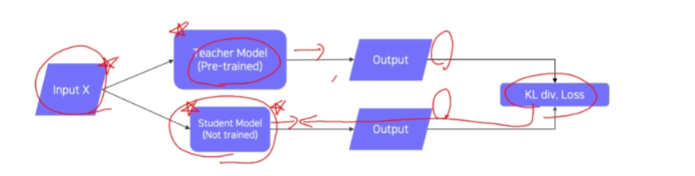
Distillation이란 증류란 뜻으로, 딥러닝에서 지식의 증류란 큰 모델로부터 지식을 추출하여 작은 모델로 전달하는 과정이라고 할 수 있습니다. 대표적인 증류 학습법으로 teacher 모델과 student 모델을 두고 두 모델이 같은 답변을 하도록 만드는 방법이 있습니다. Teacher인 영어 모델에는 영어를 입력하고, Student인 한국어 모델에는 한국어를 입력하여, 두 분포의 KL div를 줄이는 방향으로 학습시킨다면 한국어를 입력해도 영어와 같은 임베딩 벡터를 만들 수 있을 것입니다.
이 방법을 사용하면 적은 컴퓨팅 파워와 데이터로 기존 영어 모델의 능력을 다른 모델에게 전달할 수 있습니다.
=> 데이터셋
학습을 위해 영어 모델과 한국어 모델 입력에 해당하는 데이터가 필요합니다.
def __getitem__(
self, idx: int
) -> tuple["BatchEncoding", "BatchEncoding", "BatchEncoding"]:
ko: str = self.ds[idx]["ko"]
en: str = self.ds[idx]["en"]데이터 로더의 불러오는 형식에 맞게 ko, en으로 라벨링 해줘야 하며,
문제는 거래가 끊어진 경우에는 실제 거래가 이뤄지지 않기 때문에 이러한 실거래가 자료조차 찾을 수 없다는 점이다.,"The problem is that when the transaction is broken, the actual transaction is not made, so even data on the actual transaction cannot be found.","If the transaction is cut off, the actual transaction price cannot even be found because the actual transaction will not take place.",ko,en
이러한 공공 부문 이동기기 개인 영상정보 규율의 문제점을 개선하기 위해 보호 체계 및 법제 개선방안을 논의하였다.,"In order to improve the public sector mobile device personal image information regulation problem, the protection system and legal system improvement plan were discussed.",This discussed ways to improve the protection system and legal system in order to improve such a problem of the regulation of personal image information on mobile devices in the public sector.,ko,encsv 파일로 ko, en 데이터를 합쳐주는 데이터 전처리를 진행했습니다.
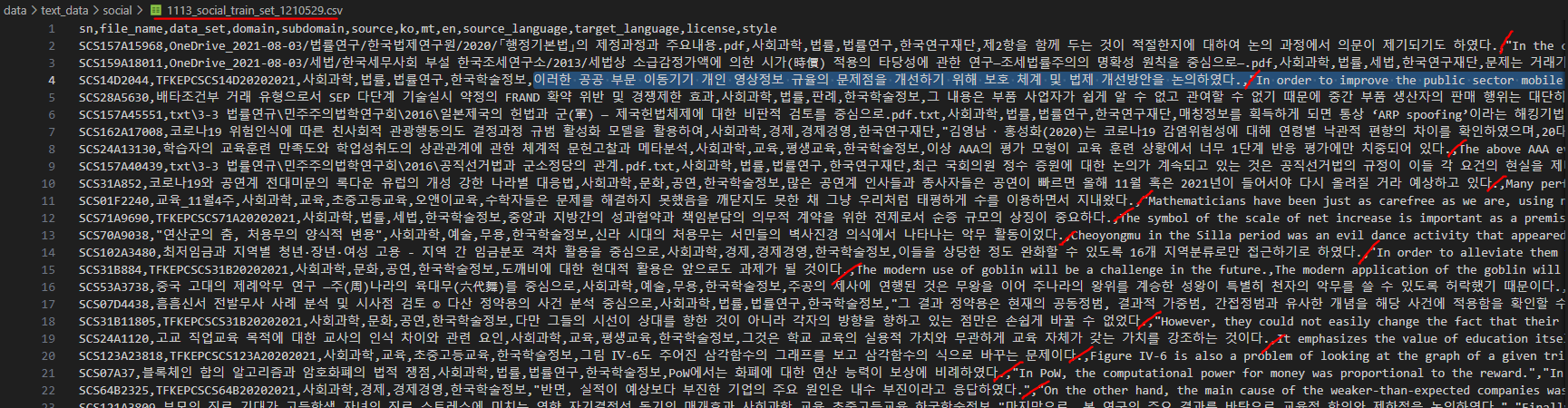
csv 파일 한 행에 영어와 한국어가 존재하도록 했습니다.
공통, 사회 과학, 기술 과학 말뭉치를 전부 사용하여,
2GB 정도의 데이터셋을 구축했습니다.
-> 학습 코드 (중요 부분)
en_tokenizer = AutoTokenizer.from_pretrained("openai/clip-vit-base-patch32")
ko_tokenizer = AutoTokenizer.from_pretrained("lassl/roberta-ko-small")지식을 증류할 모델을 로드합니다. Teacher 모델은 OpenAI 사전 학습 모델이고 한국어 모델은 로베타 기반의 small 모델을 사용했습니다.
def step(self, batch):
ko_batch, en_ko_batch, en_en_batch = batch
if self.model_type == "clip":
ko_emb = self.student.text_model(**ko_batch)[1]
en_ko_emb = self.student.text_model(**en_ko_batch)[1]
en_en_emb = self.teacher.text_model(**en_en_batch)[1]
else:
ko_emb = self.student.get_text_features(**ko_batch)
en_ko_emb = self.student.get_text_features(**en_ko_batch)
en_en_emb = self.teacher.get_text_features(**en_en_batch)
ko_en_loss = self.mse(ko_emb, en_en_emb)
en_en_loss = self.mse(en_ko_emb, en_en_emb)
loss = ko_en_loss + en_en_loss
loss_dict = {
"loss": loss,
"loss_ko": ko_en_loss,
"loss_en": en_en_loss,
}
return loss_dict매 에폭에서 teacher와 student의 mse loss를 구해서 loss를 줄이도록 학습합니다.
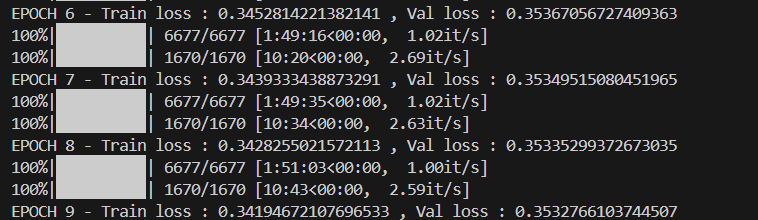
한국어에 대한 loss와 영어에 대한 loss를 합쳐서 전체 loss로 사용합니다.
+ 프롬프트 엔지니어링
우선 학습을 하는 것이 유의미한 것인가 판단하기 위해 기간을 짧게 하고 CLIP을 학습시킨 모델로 교체 후 테스트하기로 했습니다. loss가 0.35인 상태에서 모델을 테스트합니다.
기존 프롬프트 : "사무실, 회의, 프레젠테이션"
향상시킨 프롬프트 :
"회의실에서 프레젠테이션을 하고 있는 사람과 회의에 참석한 사람들의 모습. 회의실은 현대적인 디자인으로 꾸며져 있으며, 화면에는 프레젠테이션 자료가 표시되고 있습니다."
이때, 프롬프트 퀄리티에 따라서 CLIP 임베딩 결과가 달라질 거라는 피드백을 반영하여, 단답, 목록형이었던 프롬프트를 GPT로 문장형, 디테일하게 향상시켰습니다.
✅ loss 0.35 모델 테스트


프롬프트 :
"다채로운 산호초가 펼쳐진 바닷속에서 다양한 물고기들이 헤엄치는 모습. 투명한 바닷물 속에서 산호초와 물고기들의 생동감 있는 장면이 보입니다."
다채로운 산호초와 바다라는 키워드를 포착했다는 것을 봤을 때 한국어를 충분히 이해하고 임베딩하여 이미지 생성부로 전달하고 있음을 알 수 있습니다. 또한 프롬프트를 늘린 경우 임베딩 결과가 좋습니다. 하지만, 물고기들이 헤엄치는 모습은 찾아볼 수 없기에 아직 학습이 부족하거나, 프롬프트에서 누락되는 키워드가 있을 수 있습니다.


프롬프트 :
"가을철 단풍으로 물든 숲속 산책로를 걷고 있는 사람들의 모습. 나무들은 붉고 노란 단풍으로 가득 차 있으며, 길 위에는 떨어진 단풍잎들이 깔려 있습니다."
풍경의 경우 두 프롬프트 모두 비슷한 결과를 보입니다. 다만 사람의 모습이 누락된 것은 학습 부족으로 보입니다.


프롬프트 :
"해돋이를 배경으로 해변을 산책하는 사람들의 모습. 바다의 수평선 너머로 붉은 태양이 떠오르고 있으며, 해변의 모래와 물결이 평화로운 분위기를 자아냅니다."
위 경우를 봤을 때 프롬프트 최적화 전 후 모두 한국어를 이해하는 모습을 보이지만 최적화 후가 더 좋은 결과를 보입니다.
✅ koclip 1차 학습 정리
1) 학습 로그를 보면 수렴하고 있는 형태로 보인다.
2) 프롬프트를 향상시킨 결과가 이미지 생성 결과가 좋다.
3) Knowledge Distillation Model 성능도 한글을 충분히 잘 인식하는 것 같다.
-> SD + CLIP 교체 실험
학습이 진행되는 동안 학습 시킨 CLIP을 교체하여 적용할 SD 버전을 찾기 위해, 실험을 진행합니다. 이 실험에서 찾은 SD를 고정으로 진행할 것입니다.
고정 seed :1147446245
고정 프롬프트 : "의자에 앉은 한 마리의 핑크 고양이"
SD 테스트 버전 : sd 1.5, sd 2.0
CLIP 테스트 버전 : OpenAI 원본, OpenAI vit-L CLIP, Loss 0.34 학습시킨 CLIP
원본 CLIP 결과와 학습 시킨 KoCLIP 결과를 비교하여 한국어 기반으로 잘 생성되는 SD를 찾습니다.
🚨 SDXL, SD 3.0을 사용하지 않은 이유

1) 3.0 : 이미지 생성은 텍스트 벡터를 입력으로 받기에 생성기 입력 차원과 벡터 차원이 동일해야 합니다. 학습시킨 인코더의 출력 차원은 768인데 반해 3.0은 1024의 입력 크기를 가지고 있습니다.
2) SDXL : 입력 크기는 768로 동일한데, 텍스트 인코더가 총 2개로 2번째 텍스트 인코더는 현재 컴퓨팅 파워로 학습이 불가능하여, 사용할 수 없었습니다.(한계점)
1. SD 1.5
1) 학습시킨 CLIP

핑크와 고양이, 의자 조합을 최초로 생성한 조합이며, 핑크를 최초로 포착했습니다. 한국어를 완벽히 이해하고 생성까지 가능합니다.
2) 원본 CLIP

영어 CLIP을 사용해도, 한국어를 어느 정도 이해하고 생성합니다. 문맥은 맞지만 수량, 색깔 등 디테일에서 결과가 좋지 않습니다.
🚨 1.5 버전의 원본 CLIP가 한국어를 이유가 뭘까?
멘토님 : 해당 모델의 CLIP이 언어에 General 하게 학습됐을 수도 있고, 1.5 버전 파이프라인 내부에서 언어를 이해하는 추가 처리가 있을 수도 있습니다.
2. SD 2.0
1) 학습시킨 CLIP


2.0은 이미지 생성부가 한국어 임베딩 출력을 이해하지 못합니다. 한국어 CLIP으로 교체하고 한국어 프롬프트를 입력했음에도 노이즈 생성 결과를 보입니다.
2) 원본 CLIP

영어로 학습된 원본 CLIP은 당연히 한국어를 이해하지 못 합니다. 1.5 버전도 원본 CLIP은 한국어를 이해하지 못할 거라 생각했는데 실험에서 유의미한 결과를 찾았습니다.
✅ 실험 결과
1) SD 버전이 높다고 한국어 프롬프트 기반 이미지 생성 결과가 좋은 것이 아니라 SD를 제작한 회사나 SD 종류에 따라서 다르다.
2) Runway 1.5 CLIP 원본을 학습시킨 CLIP으로 수정 후 이미지를 생성한 결과, 한국어가 더 잘 반영된 것을 봤을 때 더 성능 좋은 텍스트 임베딩 학습은 의미가 있다.
3) SD 1.5로 생성했을 때 추론 시간이 6초 정도로 기존 서비스 20초, SDXL 15초에 비해 실용성이 있다.
위 결과를 토대로, SD 1.5로 고정하기로 했습니다. 또한, 현재 학습시키고 있는 CLIP의 LOSS가 줄어드는 것이 더 중요해졌습니다.
✅ 데이터 추가 + 추가 학습 결과

추가 학습한 결과 Loss가 0.32보다 더하면 과적합이 발생합니다. val loss가 가장 낮은 모델을 위에서 고정한 SD에 교체하여 동일 시드, 동일 프롬프트로 결과를 보겠습니다.


프롬프트 :
"다채로운 산호초가 펼쳐진 바닷속에서 다양한 물고기들이 헤엄치는 모습. 투명한 바닷물 속에서 산호초와 물고기들의 생동감 있는 장면이 보입니다."
원본 모델은 물고기를 생성하지 못했지만, 추가 학습 시킨 모델은 물고기를 포착하고 생성했습니다.


프롬프트 :
"가을철 단풍으로 물든 숲 속 산책로를 걷고 있는 사람들의 모습. 나무들은 붉고 노란 단풍으로 가득 차 있으며, 길 위에는 떨어진 단풍잎들이 깔려 있습니다."
원본 모델은 사람이 없지만, 추가 학습 시킨 모델은 사람들의 모습이 보입니다.


프롬프트 :
"레스토랑의 테이블 위에 다양한 토핑이 올려진 피자와 함께 식사하는 사람들의 모습. 레스토랑은 아늑한 분위기로 장식되어 있으며, 피자와 함께 나오는 샐러드와 음료들도 보입니다."
원본 모델은 피자가 올라와있는 물체를 알아볼 수 없지만, 추가 학습 시킨 모델은 테이블의 모양이 각져있기에 테이블과 지면이 구분되고, 피자 모양도 도드라집니다.


프롬프트 :
"도시의 지하철에서 출근하는 사람들의 모습. 지하철 내부는 분주하고, 사람들은 다양한 직장복을 입고 있으며, 창문을 통해 도시의 풍경이 보입니다."
원본 모델은 사람의 얼굴이 뭉개지고, 손가락이 절단 됐지만, 추가 학습 시킨 모델은 얼굴 이목구비가 잡혀있고 멀리 있는 사람도 잡았습니다.
✅ 학습 결과
학습 전 모델은 이미지를 생성하다가, 중간에 끊긴 듯한 느낌이 보이고, 누락된 키워드가 존재합니다.
반면, 끝까지 학습시킨 모델은 객체의 형태가 또렷하고 알아볼 수 있으며, 누락된 키워드가 적습니다. 결과적으로 학습이 잘 됐고, 선택한 SD는 이미지를 잘 생성하며, 기존 서비스에 비해 속도와 VRAM 비용이 적습니다. 이렇게 CLIP 학습 파트를 마무리하겠습니다.
3. 한국 특화 LoRA 개발
저희 프로젝트의 주된 목표는 한국어를 이해하는 이미지 생성기를 만드는 것이지만, 보다 한국에 특화된 이미지를 생성하기 위해서 한국을 나타내는 이미지로 LoRA를 학습합니다.


프롬프트 :
"땅에 벌레 2마리가 있습니다."
로라란, 학습 방법론으로 SD에서 Unet만 튜닝하여, 원하는 풍의 이미지를 만들 수 있도록 하는 것입니다. SD 전체가 아닌 Unet만 학습시키는 것이기 때문에, 비교적 필요한 데이터와 컴퓨팅 파워가 적습니다. 위 사진에서 오른쪽 사진은 라바 데이터로 학습시킨 LoRA를 사용하여 이미지를 생성한 결과입니다.
-> LoRA 학습
1) 원하는 풍의 이미지 수집
2) 이미지에 대한 설명 캡셔닝

먼저, 수묵화 풍으로 이미지를 생성하는 LoRA를 만들기 위해 이미지 데이터를 수집합니다. LoRA는 비교적 적은 수의 데이터로 학습 시킬 수 있다는 장점이 있기에 약 2000장 준비했습니다.

수집 한 이미지에 BLIP 자동 캡셔닝 모델을 활용하여 이미지에 대한 설명 캡셔닝을 진행합니다.

BLIP은 영어 기반 모델이라서, 한국어 번역이 수반되었습니다. DeepL API를 사용하여 전부 한국어로 번역해 주었습니다.
method : trigger 워드
caption : 이미지 설명
method를 지정해 줘야 로라 풍이 적용됩니다.


프롬프트 :
trigger word 제거 : 돈이 많은 젊은이
trigger word 포함 : 백묘법, 돈이 많은 젊은이
백묘법이라는 trigger 워드 포함 여부에 따라서 생성되는 이미지 풍이 달라지는 것을 확인할 수 있습니다. LoRA를 학습시킬 때, trigger 워드를 명시하기 때문에 trigger 워드가 없으면 LoRA가 적용되지 않습니다.
-> LoRA 학습 결과

프롬프트 :
"사진 중앙에는 확실한 나이든 사람이 있고, 웃고 있으며, 주변 배경은 산으로 둘러싸여 있다, 백묘법"
이렇게 수묵화 LoRA 학습을 마무리했습니다. 한국어를 이해하는 CLIP과 RoLA를 만들었으며, 라바, 한복 등 한국을 나타내는 컨텐츠의 LoRA를 더 많이 늘려갈 것입니다.
✅ 이미지 생성기 성능 개선 결과 정리
지금까지, Distiilation Knowledge 학습으로 AI 성능 높인 결과를 시각적으로 정리합니다.



1) 영어 CLIP : 한국어를 전혀 이해하지 못함
2) Loss 0.34 Ko CLIP : 한국어를 이해하지만, 디테일이 부족함
2) Loss 0.32 Ko CLIP : 한국어 이해 능력이 향상됨


프롬프트 :
"우주 공간에서 행성의 모습. 우주선이 여러 색상의 행성들 사이를 항해하고 있으며, 배경에는 별들이 가득 차 있습니다."
극단적인 차이가 보이는 결과물도 있습니다.



1) sd Lykon/dreamshaper-7 + 영어 clip + 영어 LoRA + 영어 프롬프트 (원본)
2) sd Lykon/dreamshaper-7 + Loss 0.34 CLIP + 영어 LoRA + 한국어 프롬프트 : 한국어를 이해하지만 퀄리티 미달
3) sd Lykon/dreamshaper-7 + Loss 0.32 CLIP + 영어 LoRA + 한국어 프롬프트 : 원본과 비슷한 퀄리티 보유
이번엔, 가장 왼쪽이 영어로 학습된 LoRA에 한국어로 학습시킨 CLIP을 적용해보겠습니다. SD는 LyKon의 Dreamshaper를 사용했습니다. 원본에 영어 프롬프트를 넣은 경우와 한국어 CLIP으로 교체한 후 한국어 프롬프트를 넣은 경우, SD의 성능이 좋을 수록 생성 이미지 퀄리티면에서도 상당한 차이를 확인할 수 있었습니다.
4. 서비스 개선을 위한 엔지니어링 최적화
지금까지는, AI 모델의 Loss를 줄이는 성능 향상 방법에 대해서 정리했습니다. 하지만 아직 아래와 같은 문제가 있습니다.
1) SD 1.5의 근본적인 성능 문제


프롬프트 :
"People sitting next to warm stoves in wooden houses in winter, the stove creates a cozy atmosphere and the snow is piled up outside."
제가 사용한 SD는 한국어를 이해한다는 이유 때문에 사용하긴 했지만, 초창기 버전이므로 최신 버전 이미지 생성기보다 퀄리티가 떨어집니다. 영어로 학습된 공식 1.5 버전에 영어 프롬프트를 넣어보아도 SDXL 보다 퀄리티 차이가 심합니다.
🚨 속도와 퀄리티의 트레이드 오프
1) 속도가 중요한 경우 : 실제 서비스에 사용할 것이기에 퀄리티가 약간 낮더라도 속도가 빠르면 실용성 존재
2) 퀄리티가 중요한 경우 : 시간이 오래걸리더라도, 퀄리티가 월등하면 퀄리티에 더욱 투자하자
회사에서는 이 두가지를 비즈니스 가치에 따라 항상 비교합니다. 저희도, 비즈니스 상황에 맞춰서 적절한 속도와 퀄리티를 찾아야 합니다.
2) 추론 속도

기존 서비스의 추론 속도가 20초 인 것과 비교하면 많이 감소시켰지만, 아직 최적화 기법 적용을 하지 않았습니다. 개선의 여지가 보이기에 최적화를 진행해야 합니다.
이 내용은 엔지니어링과 관련된 내용이므로, [최적화] 에서 다루겠으며, 여기까지, 영어만 이해하던 이미지 생성기가 한국어를 이해하게 만든 방법 설명을 마무리 하겠습니다.
'[인턴] > [롯데 Innovate]' 카테고리의 다른 글
| (작성중) [최적화] 한국어 기반 이미지 생성기 속도 및 성능 최적화 (0) | 2024.08.22 |
|---|