
개발자로 후회없는 삶 살기
[문법] Stream 본문
서론
※ 이 포스트는 다음 강의의 학습이 목표임을 밝힙니다.
https://www.youtube.com/playlist?list=PLW2UjW795-f6xWA2_MUhEVgPauhGl3xIp
자바의 정석 기초편(2020최신)
최고의 자바강좌를 무료로 들을 수 있습니다. 어떤 유료강좌보다도 낫습니다.
www.youtube.com
본론
- 스트림이란?

컬랙션이나 배열같은 데이터 소스를 표준화된 방법으로(공통된 방법) 통일화하여 사용하기 위한 것입니다. 컬랙션인 리스트, 셋과 배열 등으로 스트림을 만들 수 있고 그러면 똑같은 작업으로 처리할 수 있습니다. 데이터 소스를 스트림으로 만들고 중간 연산을 처리한 후 최종 연산을 하는 순서로 결과를 냅니다.
- 스트림 만들기
1) 리스트
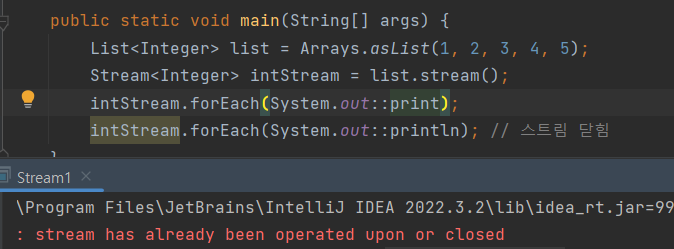
3가지 과정 중 컬랙션으로부터 스트림을 만드는 과정을 알아봅니다. 컬랙션.stream()으로 스트림을 만들 수 있습니다. 컬랙션은 스트림으로 만들기 위한 stream() 메서드를 가지고 있습니다.
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
Stream<Integer> intStream = list.stream();
intStream.forEach(System.out::println);
intStream = list.stream();
intStream.forEach(System.out::println); // 스트림 닫힘최종 연산을 한 후에 스트림이 닫히기 때문에 다시 만들어야 합니다.
Map<String, Integer> map = new HashMap<>();
map.put("1", 1);
map.put("2", 2);
map.put("3", 3);
Set<Map.Entry<String, Integer>> entries = map.entrySet(); //keySet(), values()
Stream<Map.Entry<String, Integer>> entryStream = entries.stream();
entryStream.forEach(System.out::println);Map의 경우에는 stream으로 만들기 위해서 Set으로 만들어야 합니다. 내부에 Map.Entry 타입을 가진 스트림이 생성됩니다.
2) 배열
String[] strArr = {"a", "b", "c"};
Stream<String> strStream = Stream.of(strArr); // 가변인자
Stream<String> stream = Arrays.stream(strArr);
// 문자열
Arrays.stream(inputNumber.split(""))배열을 스트림으로 만드는 법을 알아봅니다. Stream.of와 Arrays.stream 메서드를 통해 만들 수 있습니다. 문자 배열이 아니라 문자열인 경우 Arrays를 써야합니다.
// 기본형 배열
int[] intArr = {1, 2, 3, 4, 5};
IntStream intArr1 = IntStream.of(intArr);
IntStream intBasicStream = Arrays.stream(intArr);기본형 배열로부터 스트림을 만들면 기본형 스트림이 만들어 집니다. 기본형 배열은 IntStream.of를 이용하면 됩니다.
// 기본형 스트림만 가능
intBasicStream.sum();
intBasicStream.average();
Stream<Integer> intIntegerStream = Arrays.stream(new Integer[]{1, 2, 3, 4, 5});
intIntegerStream.sum(); // 사용불가기본형 스트림은 숫자인 것을 알기 때문에 sum이나 avg 같은 메서드를 가지고 있고 일반 스트림은 sum 같은 메서드를 제공하지 않습니다.
3) 무한 스트림

ints(), longs(), doubles()를 Random() 클래스에 붙이면 무한 스트림을 만들 수 있습니다.
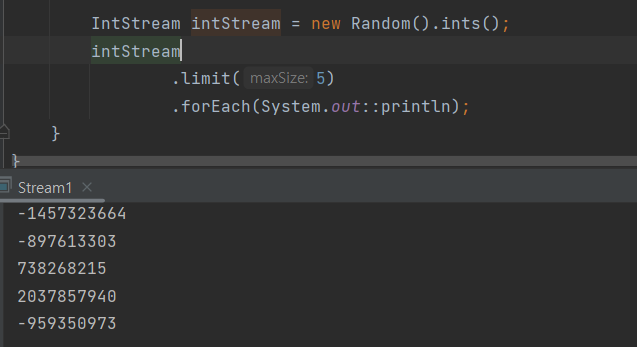
사이즈를 주면 유한 스트림도 얻을 수 있고 난수의 범위를 지정할 수도 있습니다.
4) 람다식을 이용한 스트림

람다심을 이용해서 무한 스트림을 만들 수 있습니다. iterate()에 초기값과 람다식을 넣어서 스트림을 만들 수 있고 generate에 람다식을 쓰면 스트림을 만들 수 있습니다.
Stream<Integer> generateStream = Stream.generate(() -> 1);
generateStream.limit(5).forEach(System.out::println);generate의 매개변수는 Supplier라서 입력이 없고 출력만 있는 모양으로 해야하고 iterate의 매개변수는 UnaryOperator(단항 연산자, 피연산자가 1개인 연산자)입니다.
- 스트림 연산
중간 연산과 최종 연산의 종류에 대해 알아보고 사용해봅니다.
=> 중간연산
1) skip, limit
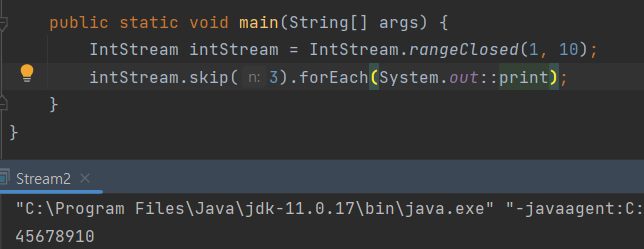
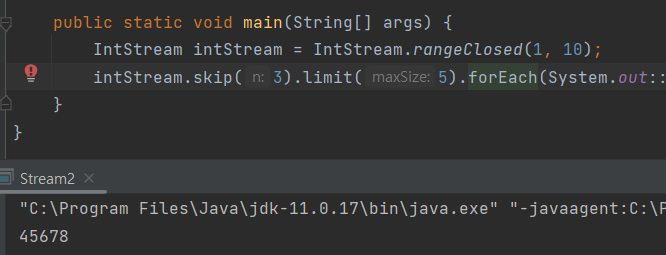
skip은 앞에서부터 n개 건너뛰고 limit 이후의 요소를 잘라냅니다.
2) filter
IntStream stream2 = IntStream.rangeClosed(1, 10);
stream2.filter(i -> i % 2 == 0).forEach(System.out::println);
stream2.filter(i -> i % 3 != 0 && i % 2 != 0).forEach(System.out::println);
stream2.filter(i -> i % 2 != 0).filter(i -> i % 3 != 2).forEach(System.out::println);필터는 Predicate 함수형 인터페이스를 인자로 줘서 조건에 True인 요소만 유지하고 나머지는 제외합니다. Predicate 인터페이스의 익명 객체를 람다로 2의 배수 조건을 주면 2의 배수만 남습니다. 조건은 && 같은 논리 연산자를 사용해도 되고 filter를 여러번 연속적으로 수행해도 됩니다.
3) distinct

중복을 제거합니다.
4) sorted

Stream에서 Comparator 함수형 인터페이스를 정렬 기준으로 줘서 정렬을 할 수 있습니다. 이때 정렬 대상은 Stream 참조변수로 제공되고 정렬 기준만 인자로 넣어주면 됩니다. 오름차순 정렬, 내림차순 정렬, 대소문자 구분 안 한 오름차순+내림차순 정렬이 가능합니다. String 클래스에 상수로 Comparator를 미리 만들어 둔 것도 있으니 가져다 사용하면 됩니다.
-> comparing 함수

sorted 메서드는 Comparator를 매개로 받는데 Comparator의 comparing 메서드가 또 함수형 인터페이스를 매개로 받습니다. 함수형 인터페이스의 익명 객체를 람다로 comparing의 인자로 넣으면 됩니다. 정렬 기준이 여러개인 경우 thenComparing을 사용합니다.
sorted의 매개변수 Comparator는 정렬의 기준이 되는 데, 대신 Comparator의 comparing 메서드를 넣었으니 Comparator의 comparing 메서드 전체가 정렬 기준이 되어야 합니다. 그 기준으로 함수형 인터페이스를 구현한 람다식으로 넣습니다.
class Student implements Comparable<Student> {
private String name;
private int totalScore;
private int ban;
public int getBan() {
return ban;
}
@Override
public String toString() {
return String.format("%s %d %d", name, ban, totalScore);
}
public Student(String name, int totalScore, int ban) {
this.name = name;
this.totalScore = totalScore;
this.ban = ban;
}
@Override
public int compareTo(Student s) {
return s.totalScore - this.totalScore;
}
}Student 클래스는 이러합니다. Student은 comparable을 구현했으니 총 점수의 내림차순을 기본 정렬로 가지고 있습니다.

스트림을 Student 객체로 만들었고 이를 반렬로 정렬합니다.

반별로 정렬 후 기본 정렬을 이어서 하면 반별로 정렬하고 반이 같은 경우 총점으로 내림차순 정렬을 합니다.
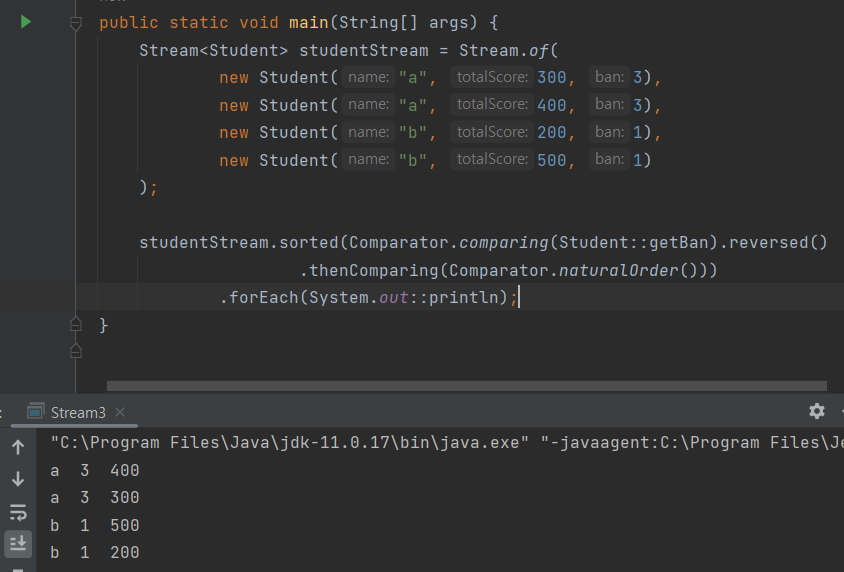
reversed를 붙이면 반을 기준으로 잡고 역순 정렬이 됩니다.
5) map

스트림 요소를 문자열이라던가, Integer로 변환하는 것입니다. 따라서 문자열 스트림이었던 원본 데이터가 Integer 스트림으로 변환될 수 있습니다.

변환을 어떻게 할 지에 대한 Function 함수형 인터페이스를 인자로 받습니다.
File[] files = {
new File("a.java"),
new File("b.txt")
};
System.out.println("a.java".indexOf('.')); // .의 인덱스를 출력
System.out.println("java".indexOf('.')); // .이 없으면 -1을 출력
System.out.println("java".substring(2)); // 해당 인덱스부터 끝까지 출력
Stream<File> fileStream = Stream.of(files);
fileStream.map(File::getName)
.filter(s -> s.indexOf('.') != -1)
.map(s -> s.substring(s.indexOf('.') + 1))
.distinct()
.forEach(System.out::println);따라서 str.indexof나 substring 등 적용할 메서드를 통해 원본 데이터를 변환하는 것을 목적으로 합니다.

map으로 File 스트림에서 파일명만 뽑고 확장자만 추출했습니다.
String[] strArr = {
"inheritance", "java", "lambda", "stream"
};
map을 사용하면 String 스트림을 Integer 스트림으로 바꿀 수 있고
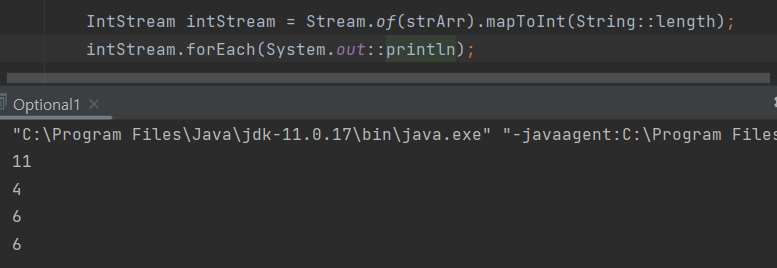
mapToInt를 사용하면 String 스트림을 IntStream으로 바꿀 수 있습니다.
6) peek
forEach와 비슷하여 Consumer를 인자로 받는데, for는 최종 연산이고 peek는 중간 연산입니다. 따라서 스트림의 중간 중간에 작업 결과를 확인하기 위해 사용합니다.
Stream<File> fileStream = Stream.of(files);
fileStream.map(File::getName)
.filter(s -> s.indexOf('.') != -1)
.peek(s -> System.out.println("filename = " + s))
.map(s -> s.substring(s.indexOf('.') + 1))
.distinct()
.forEach(System.out::println);위 코드에서 중간 중간에 확장자가 제외됐는지 디버깅 할 때 할 수 있을 것입니다. peek를 잘 활용하면 문제를 확인할 때 유용하게 쓰일 것입니다.
7) flatMap
Stream<String[]> stream = csvLines.stream()
.map(line -> line[1].split(":"))
{"a:b", "a:c"} -> (스트림("a", "b"), 스트림("a", "c"))스트림의 요소 하나 하나가 str 배열인 상황에서 map을 이용해서 변환을 하면 모든 요소를 단일 스트림으로 펼칩니다. 스트림의 요소 하나 하나가 또 스트림인 것입니다.
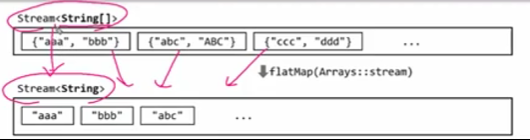
flatMap을 사용하면 여러 스트림을 하나의 스트림으로 병합하여 하나의 str 스트림이 되게 해줍니다. 여러개의 문자열 배열을 여러개의 스트림이 아닌 하나의 스트림으로 변환해줍니다.
Stream<String[]> stream = Stream.of(
new String[]{"a", "b"},
new String[]{"a", "b"}
);
Stream<String> strStream = stream.flatMap(Arrays::stream);
strStream.forEach(System.out::println);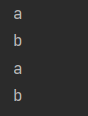
결과를 보면 Stream<String[]>인 str 배열 여러 개를 Stream<String> 하나의 스트림으로 변환하였습니다.
- optional

Integer, Long이 int 타입, long 타입을 저장하는 래퍼 클래스라면 옵셔널은 어떤 타입도 저장할 수 있는 래퍼 클래스입니다. 클래스 내부에 T 타입의 참조변수를 가지고 있어서 모든 종류의 객체와 null을 저장할 수 있습니다.
-> 필요한 이유
1) null을 직접 다루는 것은 null 예외 때문에 위험하다.
2) null 체크를 하려면 if 문이 필수라서 코드가 지져분해지는데 이를 해결한다.
Object result = getResult();
result.toString();getResult() 메서드의 반환값은 null 이거나 객체일 것입니다. 근데 만약 null이면 result.toString()을 했을 때 nullpointEx가 발생합니다. 따라서 반드시 if문이 들어가야 합니다. null일 수 있는 값을 다룰 때는 nullpointEx가 발생할 수 있다는 것과 그 때문에 if문이 필수라는 것을 알아야합니다. 이러한 문제를 해결하기 위해 나온 것이 옵셔널입니다.
옵셔널은 null을 Optional 객체 내부에 넣습니다. null 값을 직접 다루는 게 아니고 옵셔널 객체 안에 넣어서 결과가 null이더라도 result의 값은 항상 null이 아니게 됩니다. 따라서 Null 예외와 if문을 생각하지 않아도 됩니다.
String str = "";
int[] arr = new int[0];문자열도 null일 때 "" 공백으로 초기화하거나 int 배열도 길이가 0으로 초기화 해야하는 이유가 이러한 단점을 줄이기 때문입니다.
=> optional 객체 생성하기
1) Optional.of()

괄호 안에 아무 타입의 데이터를 넣어도 되며 Optional 내부에 데이터가 들어가게 됩니다.

optional의 참조 변수가 데이터의 주소를 가지고 있습니다.
2) Optional.ofNullable()

of는 null을 넣는 것은 안 되는데 그때는 ofNullable을 사용하면 됩니다.
3) Optional 빈 값으로 초기화
Optional<String> opt = Optional.empty();
=> optional에 저장된 값 꺼내오기
1) get()
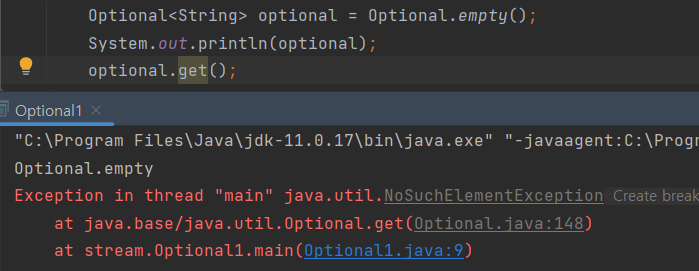
null이면 NPE가 발생하고 공백(empty)면 NoSuch 예외가 발생해서 잘 안 씁니다.
2) orElse()

Optional에 있는 값이 null일 때는 괄호 안에 있는 값을 반환합니다.
3) orElseThrow()
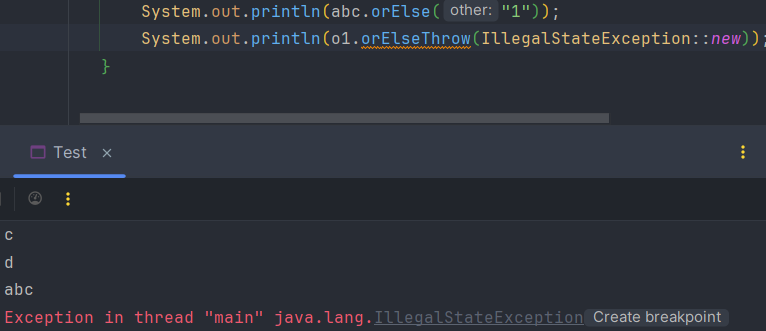
null이면 예외가 발생합니다.
4) orElseGet

Supplier를 인자로 받으며 null일 때만 불립니다.
5) isPresent()
Optional<String> s = Optional.of("123");
System.out.println(s.isPresent());
Optional<Object> o = Optional.ofNullable(null);
System.out.println(o.isPresent());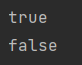
Optional의 값이 null이면 false, 아니면 true로 null이 아닐 때만, 어떠한 작업을 수행하게 할 수 있습니다.

empty는 반대로 동작합니다.
=> OptionalInt, OptionalLong, OptionalDouble

기본형 값을 감싸는 래퍼 클래스로 성능을 고려할 때 사용합니다. 람다형 Optional이 모든 객체를 감싸기 때문에 성능이 조금 떨어지기에 기본형 같은 경우는 OptionalInt를 사용합니다. 내부 타입이 T가 아니라 int입니다.
public static void main(String[] args) {
OptionalInt optionalInt = OptionalInt.of(0);
OptionalInt empty = OptionalInt.empty();
System.out.println(optionalInt.isPresent());
System.out.println(empty.isPresent());
}OptionalInt의 경우 0을 저장할 때와 empty()를 사용한 경우가 둘 다 옵셔널 내부에 0이 저장되어 구분할 것이 따로 필요합니다. 기본형 Optional은 내부에 isPresent()를 가지고 있어서 값이 있으면 즉 0일 때 true이고 null이면 false입니다.
- 스트림 최종 연산
1. 요소 검사
Predicate 조건식을 인자로 받고 boolean을 반환합니다.
1) allMatch : 조건을 모두 만족하면 참
2) anyMatch : 한 요소라도 조건을 만족하면 참
3) noneMatch : 모든 요소가 조건을 만족시키지 않으면 참
String[] strArr = {
"inheritance", "java", "lambda", "stream"
};문자열 배열이 있을 때
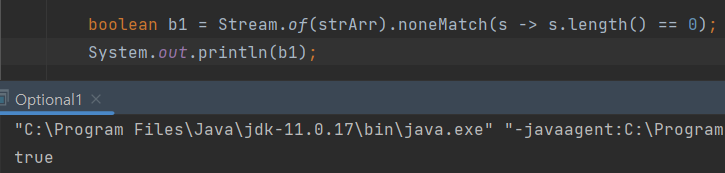
문자열 길이가 0인게 하나도 없어서 T가 나옵니다.
2. 조건에 일치하는 요소 찾기
1) findFirst : 조건에 맞는 첫번째 요소를 반환
2) findAny : 조건에 맞는 아무거나 하나를 반환

filter랑 같이 쓰며 filter 조건을 만족하면 반환합니다. 조건에 맞는 요소가 없을 수도 있어서 Optional로 받습니다.
3. reduce()
스트림의 요소를 하나씩 꺼내가며(줄여가며) 누적 연산을 수행합니다. 다음과 같은 인자를 받습니다.
identity : 초기값
accumulator : 어떤 작업을 할지
combiner : 병렬처리 결과를 합치기

스트림의 요소를 하나씩 꺼내서 카운트를 세고 하나씩 꺼내서 a에 더합니다. reduce의 내부가 위 for 문처럼 돌아갑니다.

Str형 스트림을 IntStream으로 바꾸고 한 개씩 꺼내가며 숫자를 세고
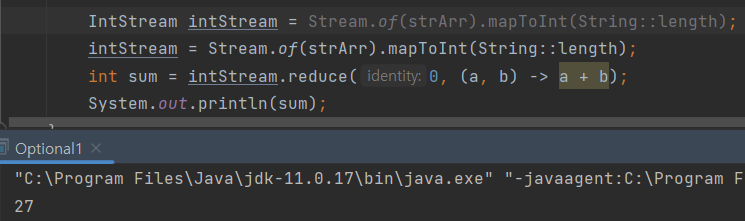
하나씩 꺼내가면서 합을 구합니다.

reduce는 초기값을 안 주면 값이 없을 수도 있기에 Optional로 반환됩니다.
5. collect()
매개변수로 Collector 인터페이스를 받아서 처리하며 다양한 기능 중 그룹별로 reduce도 가능합니다. reduce의 경우 스트림 전체를 다루고 collect는 전체에서 그룹을 나눠서 reduce를 할 수 있습니다.
-> Collector 인터페이스

collect에 매개변수로 필요한 메서드를 정의해 놓은 인터페이스 Supplier로 값을 만들어서 A에 accumulator에 있는 방법으로 누적한 후에 Finisher로 결과로 변환해서 반환합니다.
-> Collectors 클래스

Collector 인터페이스를 구현한 클래스로 이것을 가져다 쓰면 됩니다. collect()에 Collector 인터페이스를 매개변수로 넣어야 하는데 그것을 Collectors로 다 구현해 놓아서 이것을 collect()의 매개변수로 넣으면 됩니다. 아래에서 Collectors에 구현되어있는 클래스들을 알아봅니다.
1) 스트림을 컬랙션으로 변환
① toList : List로 변환
List<String> names = studentStream.map(Student::getName)
.collect(Collectors.toList());Student 스트림을 학생들 이름만 뽑고 그것을 collect() 메서드에 toList를 매개로 학생들 이름이 담긴 스트림을 String 타임 List로 변환합니다.
② toSet : Set으로 변환
Set<String> nameSet = studentStream.map(Student::getName)
.collect(Collectors.toSet());
③ toMap : Map으로 변환
Map<String, Student> studentMa = studentStream
.collect(Collectors.toMap(student -> student.getName(), student -> student));Map은 키와 벨류 쌍으로 저장해야 하니 Person 클래스가 담긴 클래스에서 id와 객체를 뽑아서 Map으로 변환합니다.
※ 스트림을 배열로 변환
Stream<Student> studentStream = Stream.of(
new Student("a", 300, 3),
new Student("a", 400, 3),
new Student("b", 200, 1),
new Student("b", 500, 1)
);
Student[] stuNames = studentStream.toArray(Student[]::new);toArray에 원하는 배열 타입을 넣어서 사용하면 됩니다.
2) 스트림의 통계
① counting() : 개수 세기
long count = studentStream.count();
Long collect = studentStream.collect(Collectors.counting());
System.out.println(count + " " + collect);
스트림의 count()를 하면 개수를 셀 수 있는데 collect도 Collectors의 counting Collectors 클래스 객체를 넣어주면 됩니다. count()가 있는데 왜 굳이 collect()를 써야 하는지는 그룹화를 해보면 알 수 있습니다. count()는 스트림 요소 전체를 세고 collect()는 그룹을 지어서 셀 수 있습니다.
② summingInt() : 합계
int sum = studentStream.mapToInt(Student::getTotalScore).sum();
// 위 코드를 풀어쓴 것
IntStream intStudentStream = studentStream.mapToInt(Student::getTotalScore);
int sum2 = intStudentStream.sum();합계를 구하는 것도 IntStream의 sum()으로 할 수 있습니다.
Integer totalScore = studentStream.collect(Collectors.summingInt(Student::getTotalScore));
System.out.println(sum + " " + totalScore);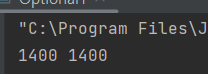
collect를 이용하면 그룹을 지어서 총점을 더할 수 있습니다. summintInt도 Collectors 클래스의 객체입니다.
③ maxBy : 최대값
OptionalInt max = studentStream.mapToInt(Student::getTotalScore).max();max 메서드의 경우 값이 없을 수도 있기 때문에 Optional로 반환됩니다.
Optional<Student> maxCollect = studentStream.collect(Collectors.maxBy(Comparator.comparingInt(Student::getTotalScore)));
System.out.println(max.orElse(123));
System.out.println(maxCollect.orElse(null));
최대값의 기준을 주면 최대값을 구할 수 있습니다. 반환타입으로 Optional의 T에 Student가 들어가므로 학생 객체가 들어갑니다.
3) reducing
// reduce
IntStream intStream = new Random().ints(1, 46).distinct().limit(6);
OptionalInt intStreamReduce = intStream.reduce((int a, int b) -> a * b);
// collect의 reducing
intStream = new Random().ints(1, 46).distinct().limit(6);
Optional<Integer> collectReduce = intStream.boxed().collect(Collectors.reducing(((integer, integer2) -> integer * integer2)));
System.out.println(intStreamReduce.orElse(123) + " " + collectReduce.orElse(null));
둘의 차이는 전체를 대상으로 하냐, 그룹을 대상으로 하냐입니다. 똑같이 초기값과 작업 방식을 인자로 넣어야합니다. 기본적으로 collect의 경우 Optional에 제네릭 타입이 들어갑니다.
4) joining()
String collect = studentStream.map(Student::getName).collect(Collectors.joining());
System.out.println(collect);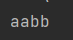
학생 이름을 뽑아서 하나의 문자열을 결합하고 싶을 때 map으로 학생 스트림에서 이름만 뽑고 collect()에 joining을 인자로 주어 합칠 수 있습니다.
※ parallel() : 스트림 병렬 처리
5) 스트림 분할
collect는 아래 2개의 메서드와 같이 써서 그룹을 나누고 작업합니다.
① partitioningBy() : 스트림을 2 분할
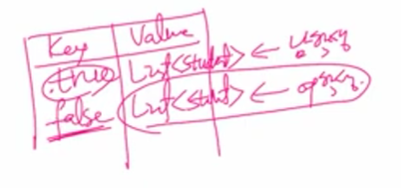
partitioningBy는 Predicate를 매개로 받아 분할 기준으로 삼습니다. 학생들을 성별로 나눌 때 2분할을 할 수 있고 나눈 결과를 Map에 저장하게 되는데 키가 bool이고 벨류가 List인 학생 목록입니다. 키가 bool인 이유는 isMale을 기준으로 나누는데 isMale이 bool 타입이라서 그렇습니다. 기준이 되는 값이 key로 사용됩니다.
Map<Boolean, List<Student>> stuBySex = studentStream.collect(Collectors.partitioningBy(Student::isMale));
List<Student> male = stuBySex.get(true);
List<Student> female = stuBySex.get(false);

true가 남학생 목록이 나오고 false로 하면 여학생 목록이 나옵니다.
Map<Boolean, Long> stuNumBySex = studentStream.collect(Collectors.partitioningBy(Student::isMale, Collectors.counting()));
Long maleCount = stuNumBySex.get(true);
Long femaleCount = stuNumBySex.get(false);
System.out.println(maleCount);
System.out.println(femaleCount);collect는 ','로 구분하여 나누고 그룹에 또 작업을 할 수 있습니다. collect(partitioningBy(Student::isMale, counting()))을 하면 성별로 그룹을 나누고 수를 세서 Map에 저장하게 되면 키는 bool로 동일한데 벨류는 Long형입니다.
Map<Boolean, Map<Boolean, List<Student>>> failedStuBySex = studentStream.collect(partitioningBy(Student::isMale,
partitioningBy(s -> s.getTotalScore() < 250)));
List<Student> failedMaleStudent = failedStuBySex.get(true).get(true);
List<Student> failedFemaleStudent = failedStuBySex.get(false).get(true);
failedMaleStudent.forEach(System.out::println);
failedFemaleStudent.forEach(System.out::println);파티션은 둘로 나누고 또 둘로 나눌 수 있습니다. 남과 여로 나누고 남에서 합, 불 여에서 합, 불로 나눌 수 있습니다. collect(partitioningBy(), partitioningBy())로 하면 됩니다. 이 경우 남자 불합격자를 구하려면 True에서 또 True를 사용해야 합니다. 두번째 파티션 기준이 250보다 작은 게 참이니깐 False로 하면 합격자를 구할 수 있습니다.
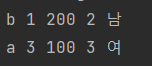

Map에 벨류가 또 Map으로 들어간 모양입니다.
② groupingBy() : 스트림을 n 분할
Map<Integer, List<Student>> stuByBan = studentStream.collect(groupingBy(Student::getBan, toList()));
반을 기준으로 나누면 1, 2, 3반 N반 학생들을 n분할 할 수 있습니다. toList()를 넣어서 나눈 결과를 벨류에 List로 저장합니다.
Map<Integer, Map<Integer, List<Student>>> stuByHakAndBan = studentStream.collect(groupingBy(Student::getHak,
groupingBy(Student::getBan)));마찬가지로 다중 그룹화를 하여 value 안에 또 map을 그릴 수 있습니다.
'[백엔드] > [Java | 학습기록]' 카테고리의 다른 글
| 디자인 패턴 PART.빌더 패턴 (0) | 2023.08.17 |
|---|---|
| 디자인 패턴 PART.추상 팩토리 패턴 (0) | 2023.08.13 |
| 디자인 패턴 PART.팩토리 메서드 패턴 (0) | 2023.08.13 |
| 디자인 패턴 PART.싱글톤 패턴 (0) | 2023.07.25 |
| [문법] 자바에서 제공하는 함수형 인터페이스 (0) | 2023.06.13 |



